数据集基础
2021-6-29 About 42 min
数据集
数据集是OLAP分析的Cube(数据立方体),可以提前定义查询、聚合表达式、动态时间漏斗、数据权限等。 在用户数据模型比较稳定的前提下,可以减少相同数据集下不同表报设计时重复的填写查询脚本、新建聚合表达式工作。
CBoard 的数据集为敏捷轻模型,任何一条简单的查询输出都可以当做一个 cube 查询来使用,cube 修改避免了常规数据建模、修改、发布测试的繁琐过程。
打个比方,第一次业务需求你可能选择了,a,b,c,d 四个列作为聚合维度建立了一个 Cube 查询
SELECT a, b, c, d
FROM fact a
JOIN dima ON ...
JOIN dimb ON ...
1
2
3
4
2
3
4
之后有了新的需求,需要引入维度 e, f, g 列,常规的报表工具需要重新引入表、更新模型定义、发布,这个时候 CBoard 轻模型的优势就体现出来了只需要简单的修改或者复制之前的模型再修改一下查询
SELECT a, b, c, e, f, g
FROM fact a
JOIN dima a ON ...
JOIN dimb b ON ...
1
2
3
4
2
3
4
提示
您甚至可以更换一个数据源、完全重写查询,仅需要保证旧查询使用的字段都包含在修改之后的查询字段中
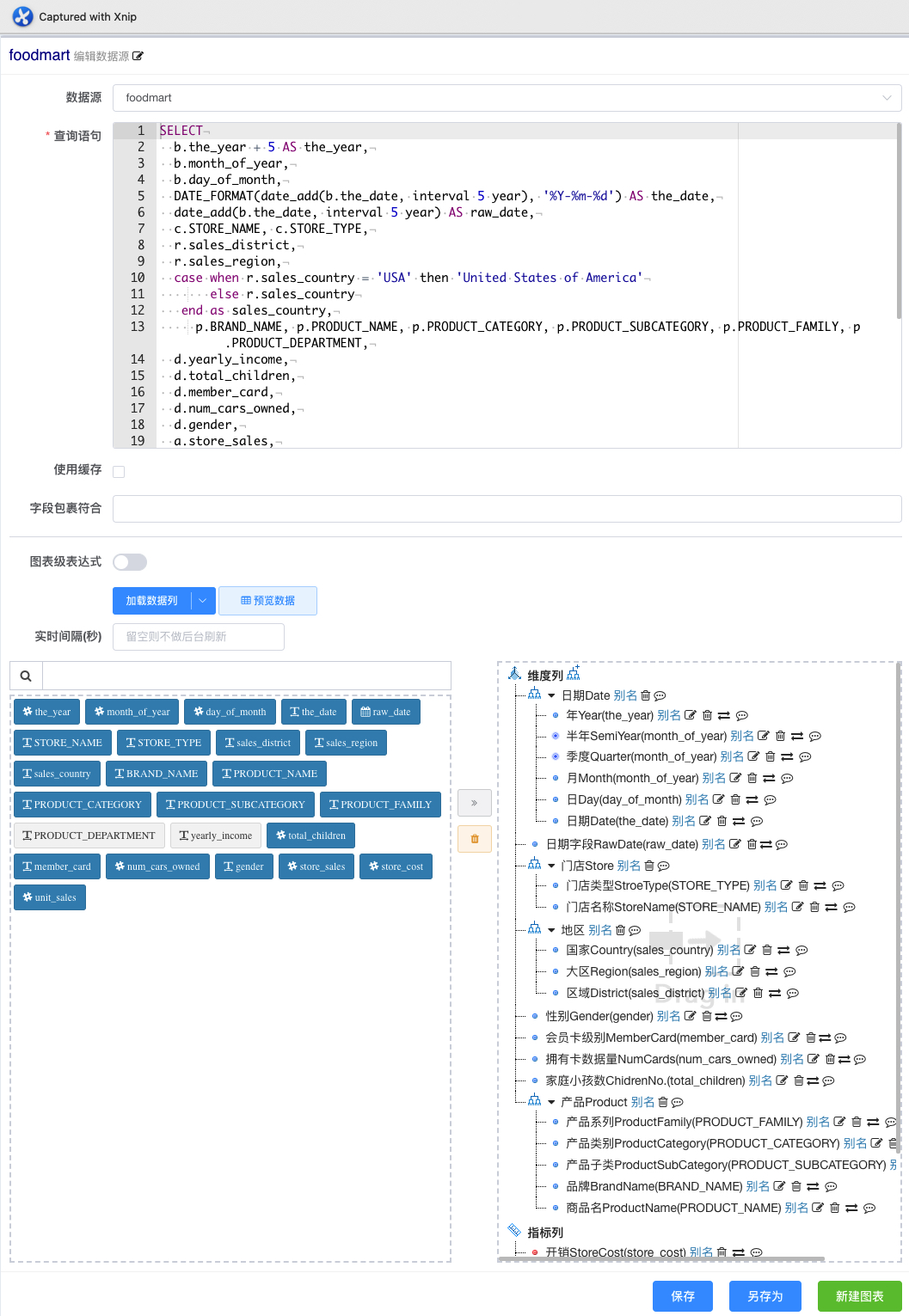
# 数据集模型定义
数据集的 schema 包含维度列、度量列、聚合表达式、预定义漏斗
- 选择数据源,填写对应的查询脚本,JDBC 数据源为查询 SQL,读取数据
- 读取数据成功之后,
原始列/可选列和 Schema 空树出现在页面下方 - 拖拽左边方框的列到右边维度节点/度量节点下方,也可以通过点击左边的
可选列,快速把列添加到 Schema,默认添加到维度节点,之后可通过功能键切换到度量 - 一个列可在不同的维度层级下多次使用,如:年->月->日,年->周->日
- 加入 Schema 树的列可以编辑修改
别名 - 层级是图表下钻、上卷的路径基础
- 计算表达式和过滤组通过点击
添加新建
提示
- 维度列在图表设计时只能拖拽到维度栏;
- v1.5.1之前的版本指标(度量)列只能拖拽到指标栏,1.5.1之后的版本指标可以拖拽到维度用作直方图分析
- 聚合函数设计时可以改变, 默认为 sum 求和
# 建模建议
建议
正常情况下我们建议让有基础数据仓库建模经验的技术人员进行维度建模,建好模型之后自助分析、看板设计阶段交付非技术、业务使用
这样做的好处是专业的人员统一管理模型,交付的模型更加利于后期多场景重用分析,查询性能也更加可控

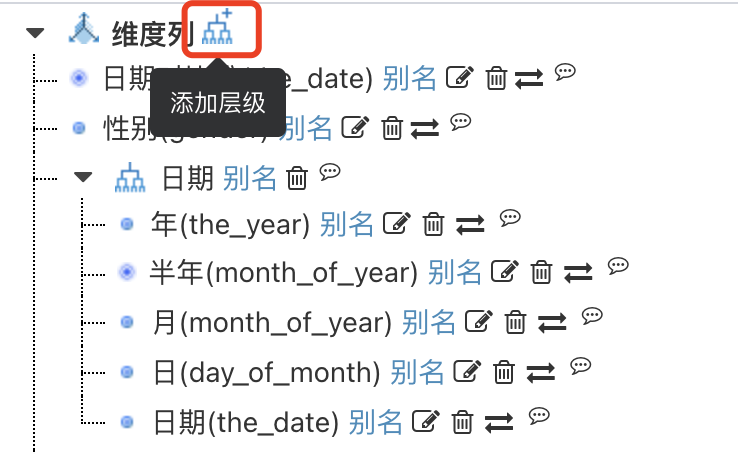
# 维度层级
维度层级是图表在固定路径上下钻、上卷的路径基础, 常用于交叉表、柱线图、饼图的下钻操作
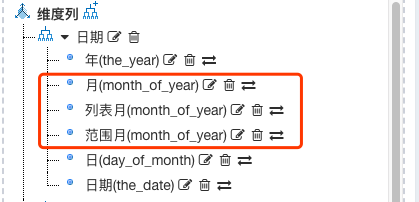
# 衍生维度、定制维
原始数据列在模型上可以多次重复使用, 除了定义不同的下钻维度层级之外, 还能对相同列进行不同的维度分组定制; 下面的例子演示了通过不同方式对月份分组上半年/下半年,
当然这个例子只是简单为了做功能演示, 真实数据你可以已经包含上下半年信息
- 点击维度节点上的
编辑按钮进入定制维弹框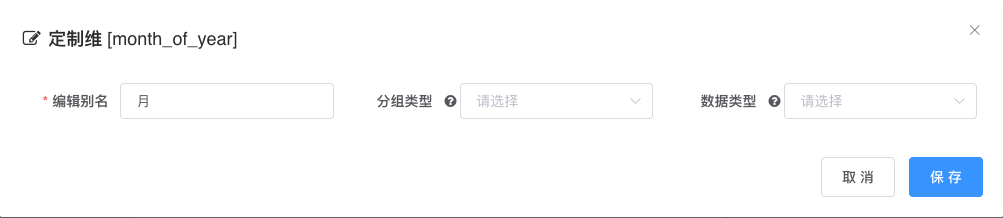
# 列表定制
分组类型选择列表, 列表分组适合给字符型维度进行分组
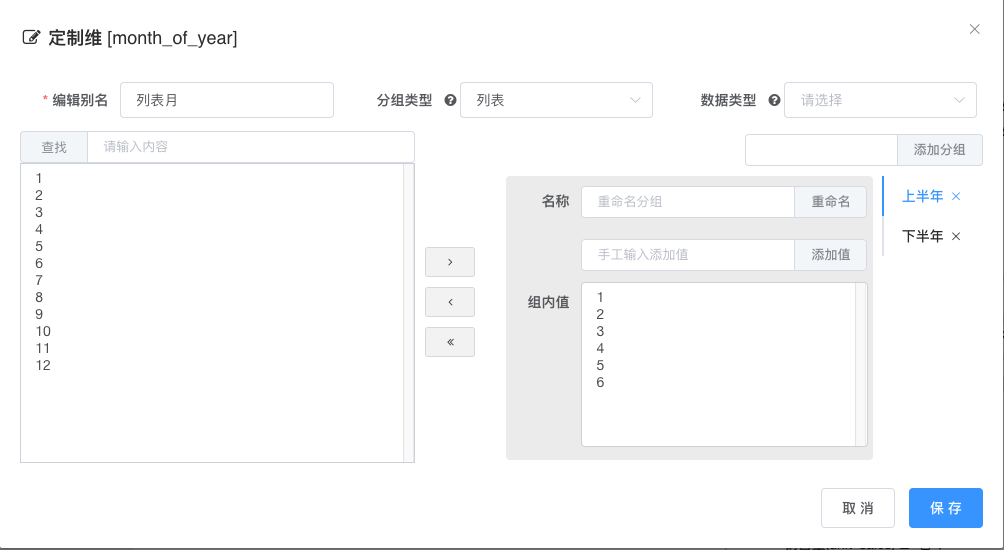
左边栏为该原始数据列所对应的值, 右边栏为分组定义,
- 输入别名
- 在右边栏最上方输入分组名框, 输入分组然后点击添加分组
- 激活分组标签页, 然后对对该分组进行重命名和分组成员定义, 如果分组成员比较简单或者该列对应的结果集过大, 手工输入成员值之后添加
- 不在分组内的值将被分为
其他分组 - 对维度进行分组之后大部分情况下改变原有列的数据类型, 为了让服务端能够生成正确的查询脚本, 最好还需要在窗口首行指定分组之后的
数据类型, 不指定默认为字符串类型 - 分组编辑完成之后点击保存, 取消则视为放弃本次编辑
# 范围定制
分组类型选择范围, 范围分组适合给数值型维度进行分组
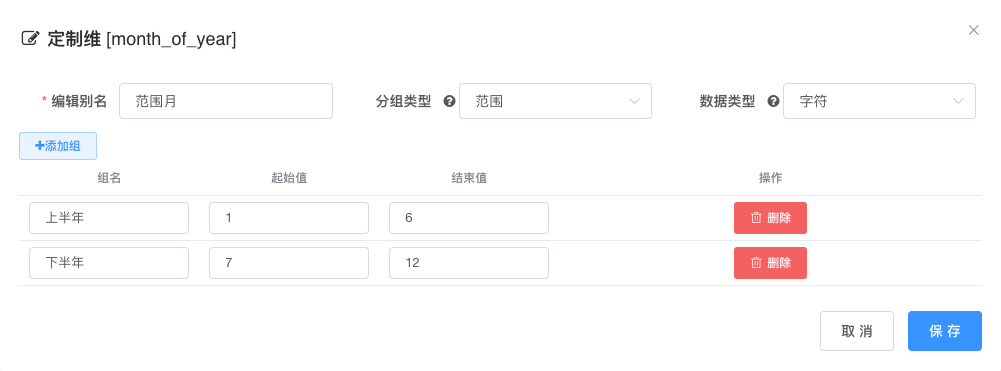
- 输入别名
- 选择分组之后的数据类型, 我们这里把原本 1-12 的数值型月份变成了
上半年和下半年两个文本成员, 所以选择数据类型为字符 - 添加分组
- 编辑分组名, 起始值, 结束值, 注意分组区间为闭区间
- 编辑完成保存
# 脚本定制
分组类型选择脚本, 脚本分组适用于对 sql 比较熟悉的用户, 可以定义任意复杂类型的分组
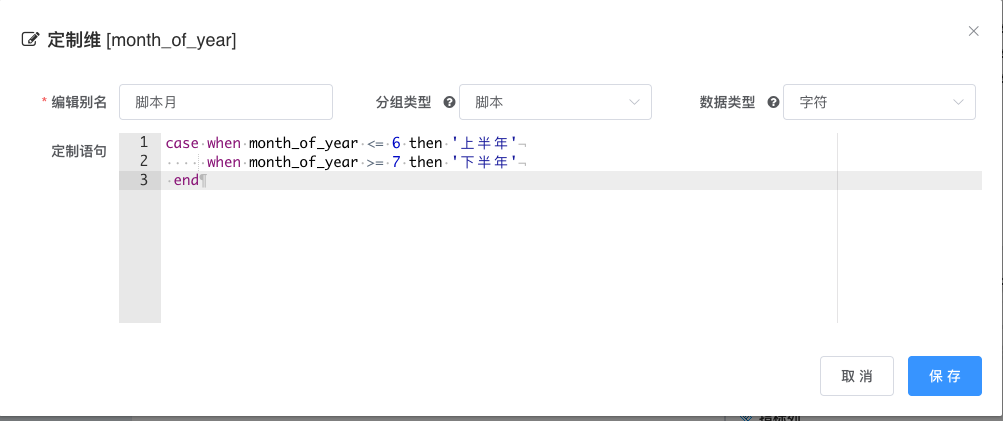
注意
分组脚本不需要再指定别名;
# 组外成员处理
对于维度组外成员,如果需要显示,可以设置组外成员处理,默认为维持原值,可以配置维持原值或设置为统一值,如果不需要统计显示,可以设置过滤组外成员
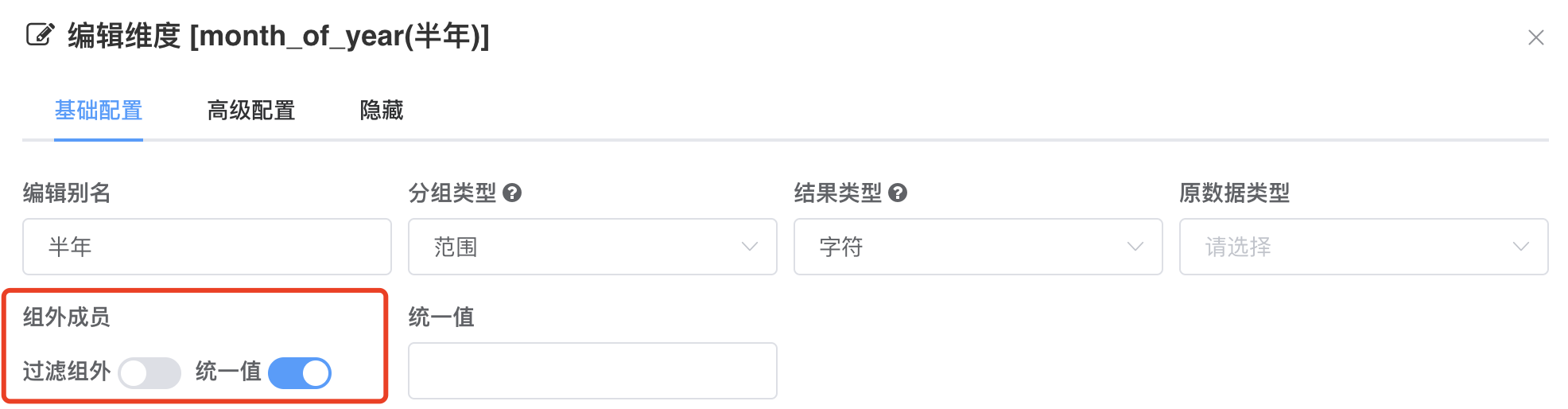
注意
如果衍生维度的数据类型与原始字段的数据类型不一致,Clickhouse会报错,如下面所示,case 结构中同时出现字符与数字,在数据库没有 做兼容处理的情况下将引起报错, 解决方案为设置组外成员统一值,或者过滤组外成员
SELECT
`the_year` AS c_0,
CASE
WHEN `month_of_year` IN (1, 2, 3) THEN '上半年' -- 字符类型
ELSE `month_of_year` -- 数字型
END AS c_1,
...
1
2
3
4
5
6
7
2
3
4
5
6
7
SOL 错误 [386] [07000]: Code: 386. DB:Exception: There is no supertype for types String, Int8 because some of them are String/FixedString and some of them are not;
# 维度字典功能v1.9
维度字典在数据集编辑->维度节点高级配置栏->维度字典(原维度可选值查询)中配置

支持多对一处理
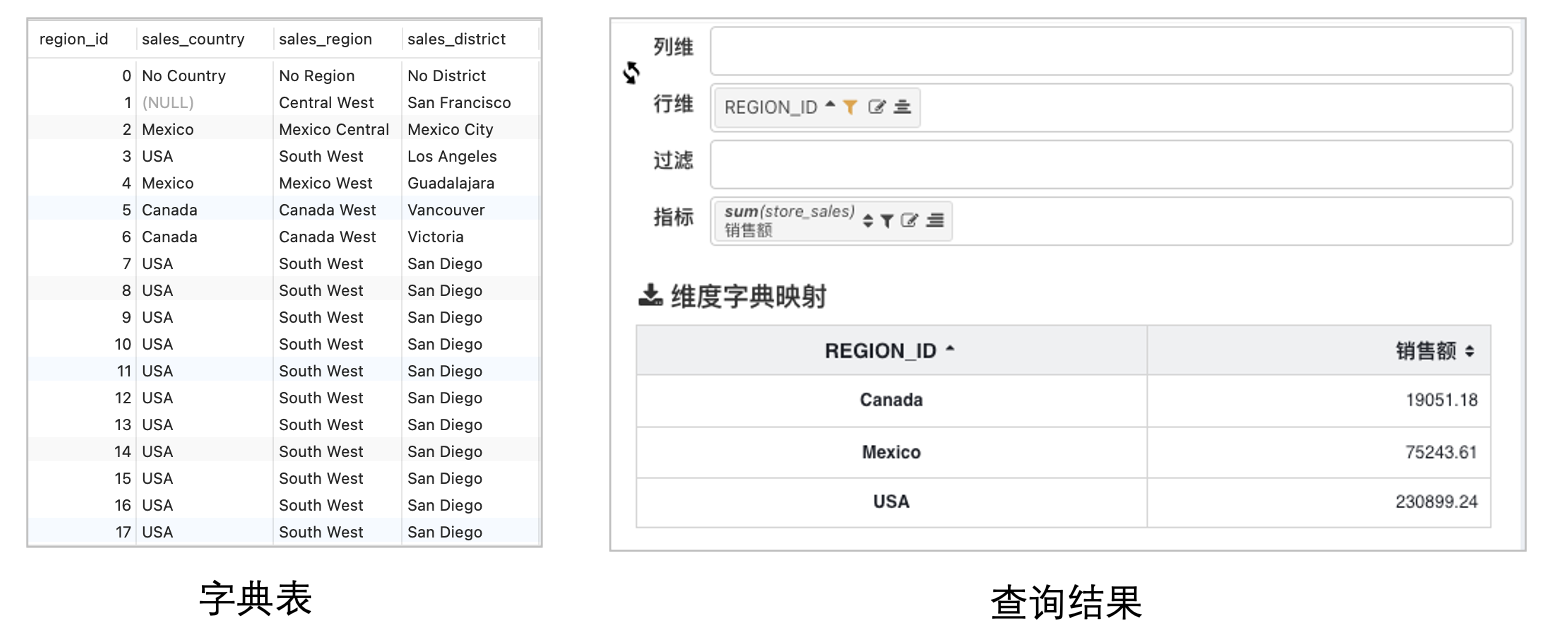
聚合数据查询
维度字典的配置,不会改变汇总查询的结构,从上面的案例可以发现聚合字段依旧是region_id,region_id与country之间是多对一的的关系,即多个region_id对应同一个国家, 汇总查询按region_id汇总,但是我们的数据引擎会在此基础之前再进行一次汇总计算,实现按字典映射值sales_country的粒度汇总
SELECT `REGION_ID` AS c_0,
SUM(`store_sales`) AS v_0
FROM (
-- dataset view
) cb_view
WHERE `REGION_ID` NOT IN (1)
GROUP BY `REGION_ID`
1
2
3
4
5
6
7
2
3
4
5
6
7
跨库、跨源关联
维度字典查询可以与数据集为不同的库或者数据源,因此可以利用维度字典实现跨库跨源数据关联,典型场景如: Elasticsearch数据集维度映射到关系数据的字典表
字典过滤
对有配置维度字典的维度过滤,维度成员输出按映射结果分组,选定值为映射值,多维分析引擎会把映射值还原为原值过滤
支持用户在选定值直接输入原始值
如果输入的选定值在字典表找不到映射关系,则不做映射直接用原值过滤
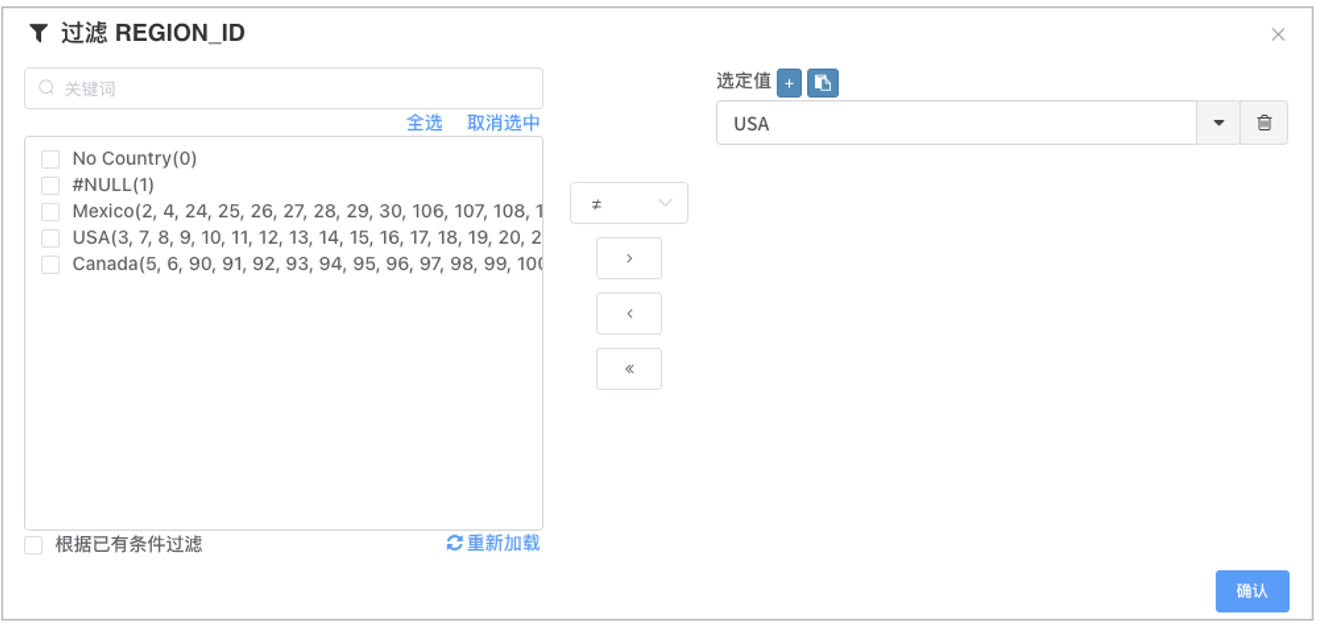
SELECT `REGION_ID` AS c_0, `sales_region` AS c_1,
SUM(`store_sales`) AS v_0
FROM (
-- dataset view
) cb_view
WHERE `REGION_ID` NOT IN (3,7,8,9,10,11,12,13 ....)
GROUP BY `REGION_ID`, `sales_region`
1
2
3
4
5
6
7
2
3
4
5
6
7
# 聚合表达式
编辑聚合表达式并测试正确,表达式是用于聚合后再计算.
如:Math.log(sum(columnA)/count(columB))表达式的编写
- 表达式可以编写的时候, 写点击选择
聚合栏聚合函数和可选字段辅助输入; - 表达式之间可以引用已有,
可选表达式引用定义好的表达式的时候注意不要成环, 避免解析死循环
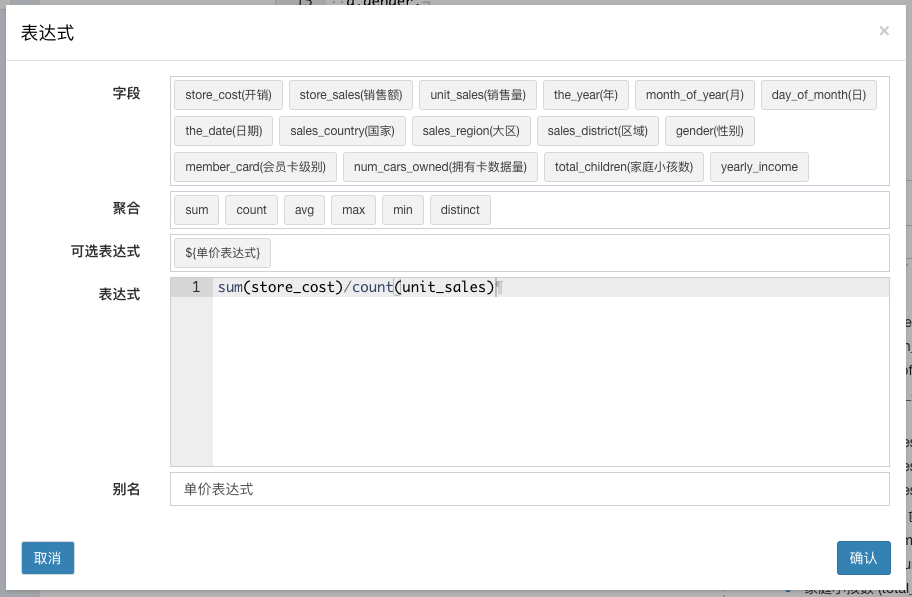
注意
聚合表达式中使用的字段必须与聚合函数成对出现,否则聚合表达式将会影响聚合颗粒度引起计算错误
如: 维度字段使用了年度,sql对应的聚合为group by year, 当聚合表达式中出现了不在group by中的字段则改查询就不正确了
-- 正确
select year, sum(cost)
from t
group by year
-- 错误
select year, unit * sum(cost)
from t
group by year
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
- 数据集中预定义的聚合表达式在图表设计时不支持修改
sql的count distinct
表达式里面的distinct(col)与sql的count(distinct col)等价, 直接写count(distinct col)是错误的写法
# 条件聚合
汇总统计中维持原始输入
怎么实现count(case when col > 10 then 1 else 0 end)
加个引号就可以了, 表达式会把里面的语句当成一个整体 count("case when col > 10 then 1 else 0 end")
# 解析自定义/特定聚合函数1.9
默认的的汇总类型只支持常规的sum/avg/max/min/count/distinct(等同于数据库中const(distinct column))
自定义聚合函数支持用户使用数据库特有的汇总函数,比如clickhouse的分位数统计函数

自定义聚合函数的配置在可选表达式中添加表达式语法如下:
[aggType](column)aggType为聚合函数名,column为列名,如:[quantile](salary)
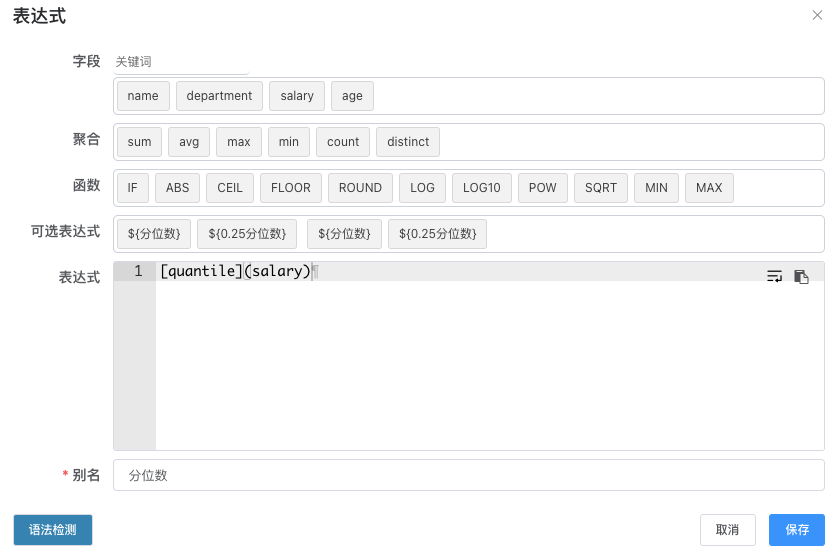

提示
使用自定义聚合函数时暂时忽略语法检测,后续版本中会完善语法检测功能
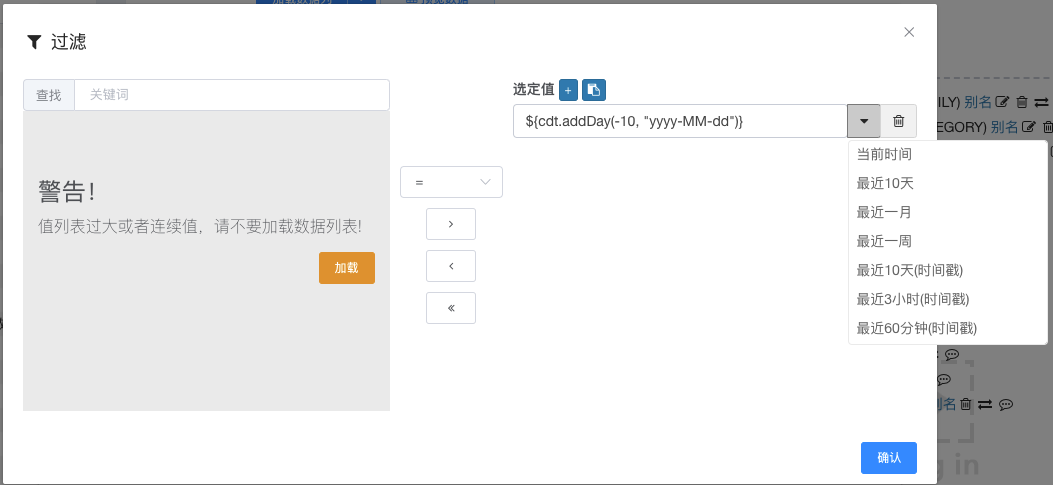
# 预定义漏斗(过滤器)
用于预定义动态日期窗口,点击下拉选择动态时间表达式模板,模板中的值可以编辑文本。用户可根据自己的需求改成任意大小时间窗口。
# 预定义组合过滤
- 原有的过滤器组合只能对原始数据列进行过滤而且不同列之间的关系只能是简单的与运算(AND), 即必须都成立;
- 如果想要过滤
男性或者国家为美国这样的条件或者更加复杂的过滤条件则无法完成; - 企业版 0.5.1 在添加
定制维功能之后对过滤器也进行了相应的改进, 过滤器不再直接在列上定义, 而是在模型维度节点上进行过滤;
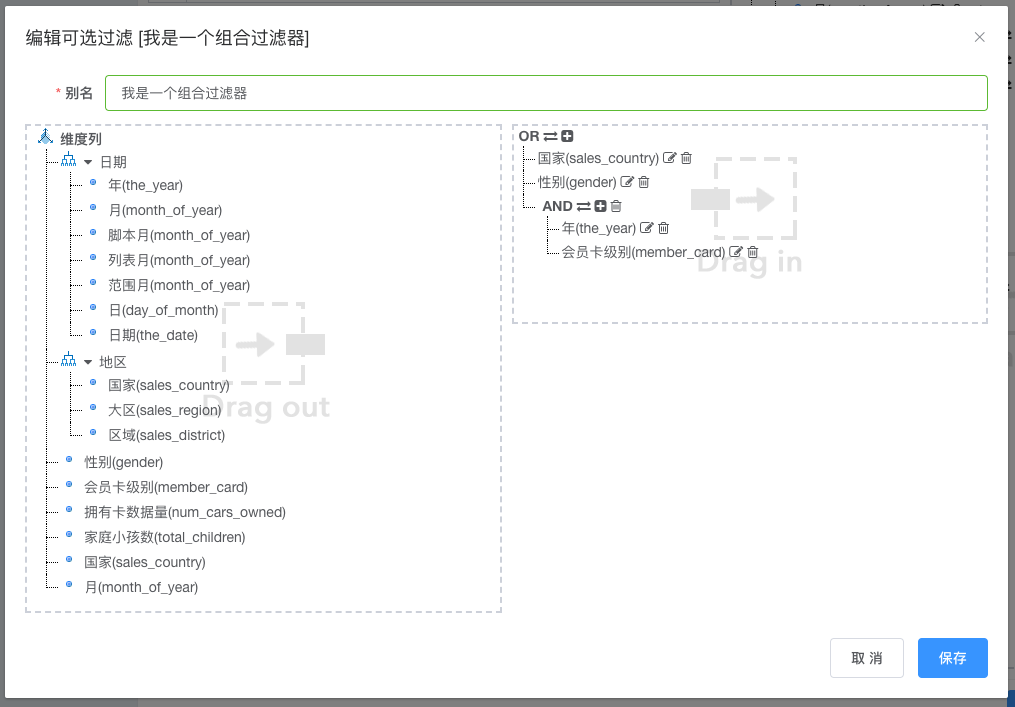
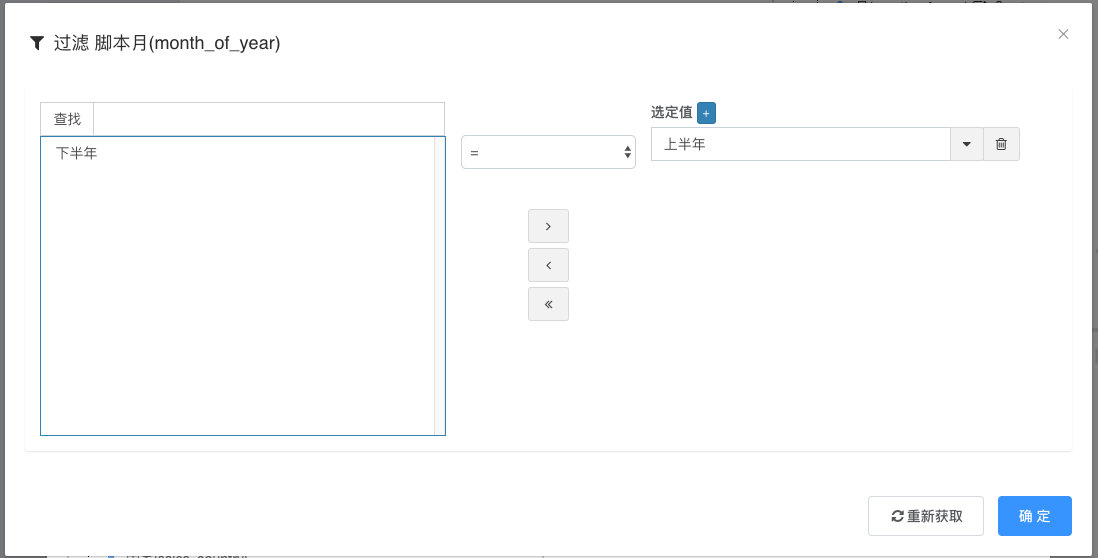
- 如前面我们演示了新增一个半年的维度, 之后用户可以在过滤器里面过滤
上半年即可; 否则按原有数据列过滤逻辑, 过滤上半年需再次选定上半年所有月份;
# 准实时数据集/看板刷新
看板是如何做刷新的? 我们知道一个看板里面可以组合来自不同数据集的图表, 但是不是所有的数据集的图表都需要刷新 因此我们把看板上图表的刷新和数据集绑定在一起了, 在设计数据集的时候设置实时刷新时间间隔, 可以保持空,留空则不做后台刷新,填入大于 0 的值, 看板展示的时候里面要是存在设置了刷新间隔的数据集所创建的图表, 该图表就会按设置的时间间隔重新读取数据并更新
# 数据集权限模板企业版 v1.2
通过数据集权限模板可以控制数据集对不同用户的数据访问权限,查询模板是可以查询外部系统权限数据,这样便可以方便用户把BI系统与外部系统的权限进行集成
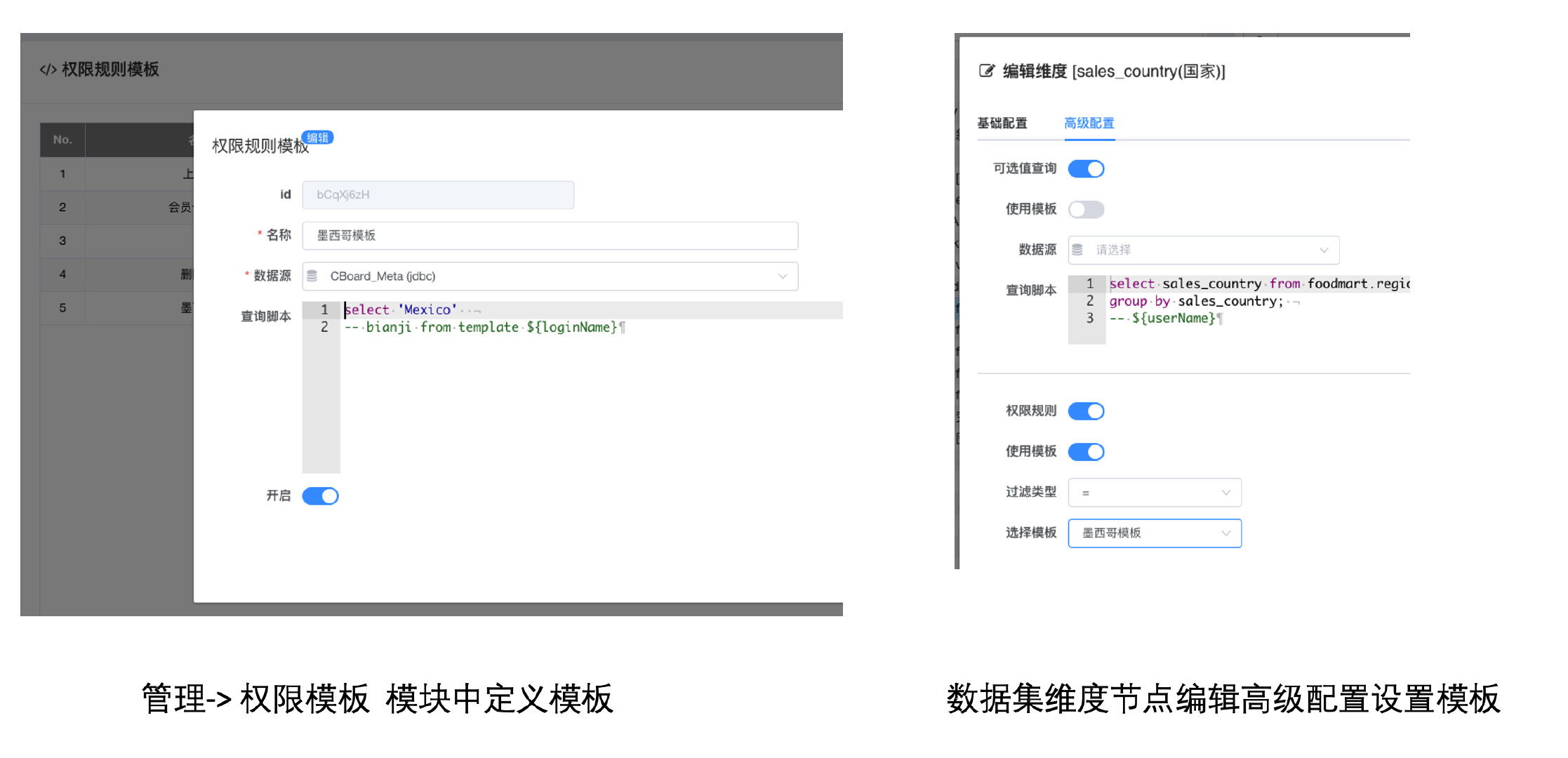
操作步骤:
- 编辑维度节点,高级配置栏开打权限规则开关
- 可以使用直接查询,选定权限数据所在的数据源连接->编写查询,查询中可以通过
${loginName}变量控制区别用户权限范围,查询首列为当前维度限定的数据范围 - 也可以使用权限模板(查询模板)中预定义的模板
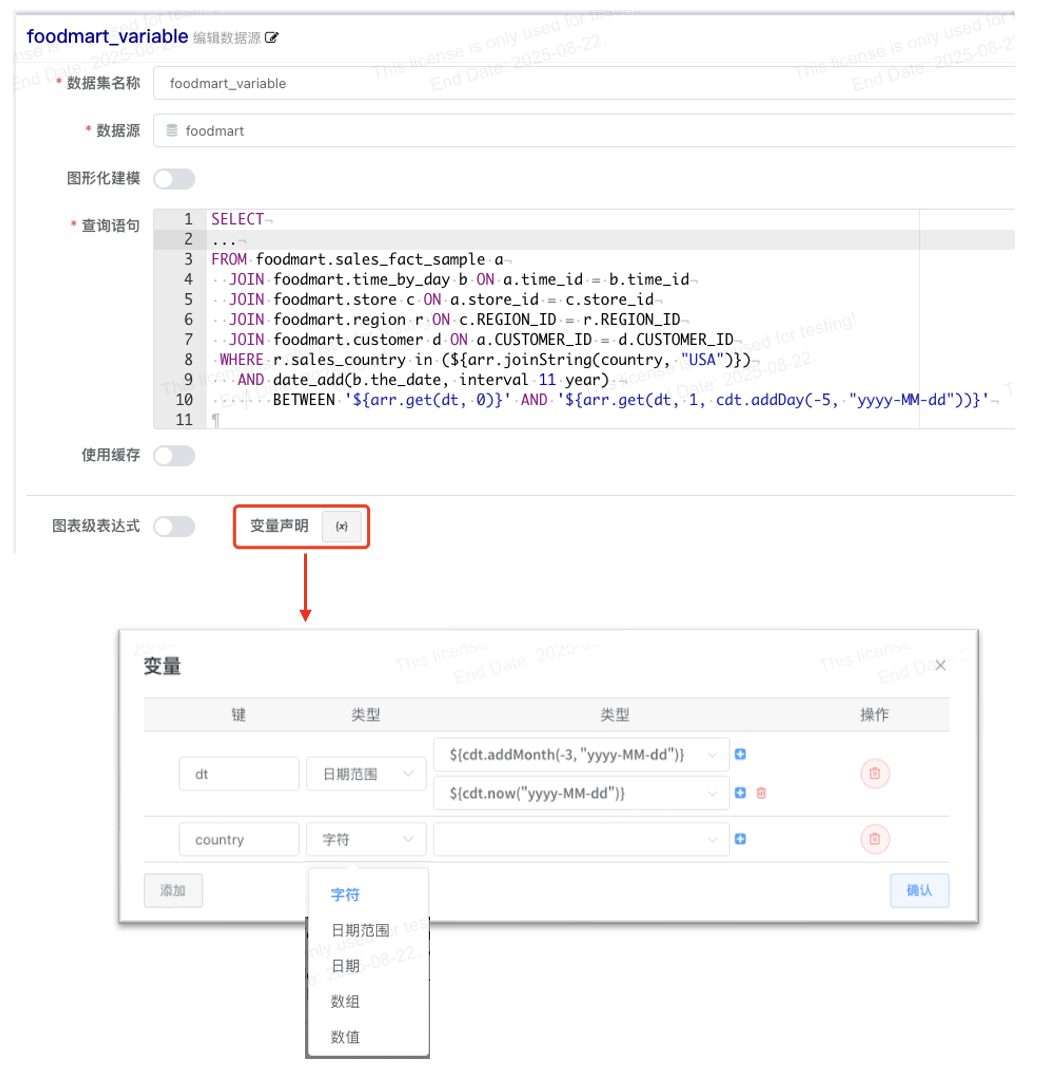
# 数据集变量声明v1.13
数据集查询中使用变量并不需要提前声明,只要下游自助分析中赋值即可生效,但是不方便地方在于在自助分析页面中不知道数据集中使用了哪些变量,以及变量的类型是什么。
从数据集和自助分析两个模块定位的使用者角色来看,数据集设计用户通常为有技术背景的用户,自助分析面向业务用户,因此为了让业务用户能在使用数据集时更加方便,可以选择在数据集开发阶段提前定义好
数据集支持的变量以及变量类型
数据集设计阶段声明变量支持
- 配置变量类型,不同的变量类型在自助分析页面变量赋值对应不同的输入形式
- 设置变量的默认值(也可以不设置)
- 默认值支持使用变量
提示
数据集查询中数组变量获取建议使用arr.get()函数传参设置,因为carr.get()能够在变量为空白字符和null两种情况下更安全的设定默认值
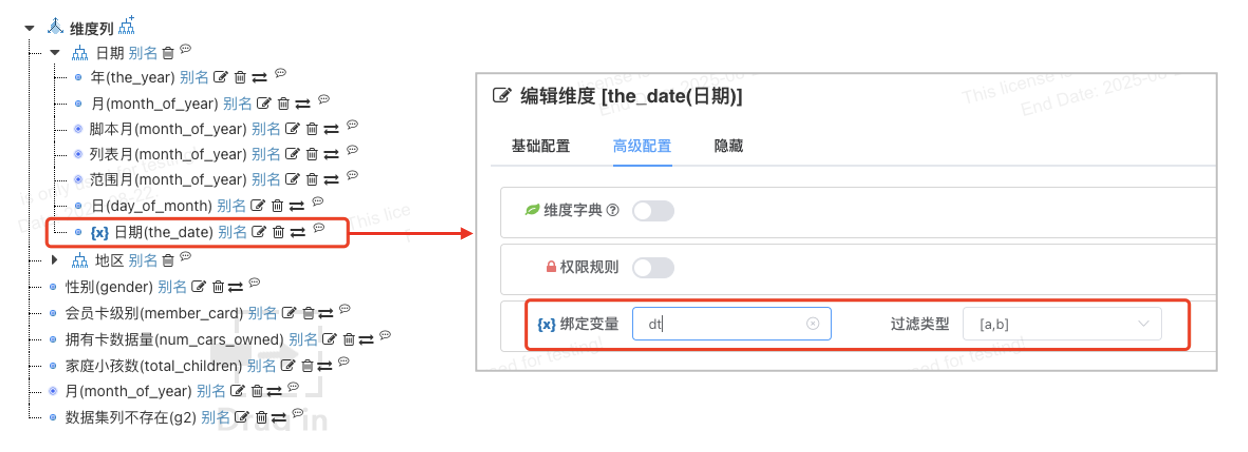
# 维度绑定变量配置v1.13
将数据集维度绑定变量之后,自助分析过程中维度过滤条件可以隐式赋值到变量,从而进一步实现变量赋值的无感化、简单化,降低业务人员对变量赋值使用门槛
- 通过过滤类型的限制确保了变量赋值的正确性, 如日期范围查询过滤类型为闭区间,必须设置两个值
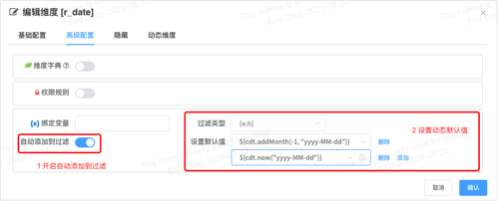
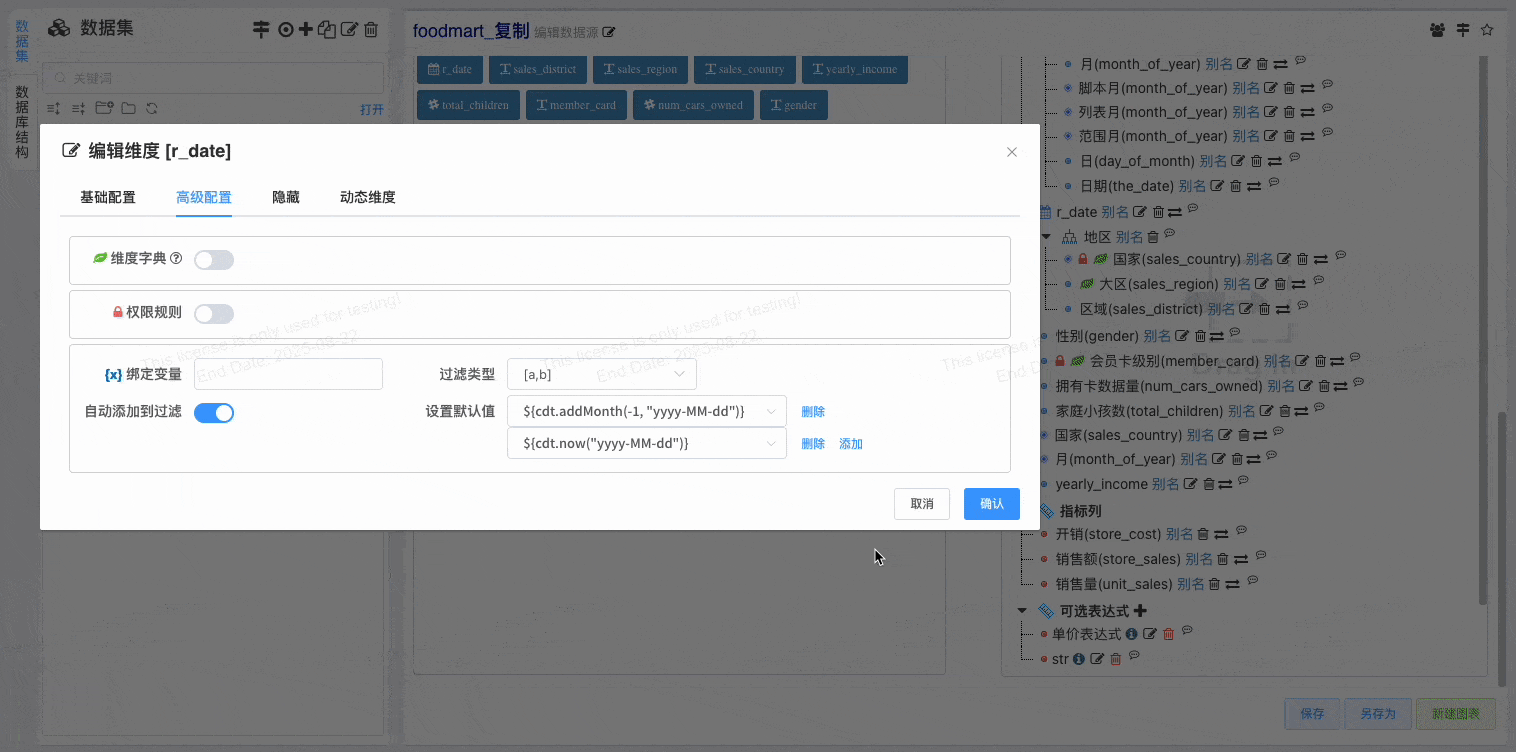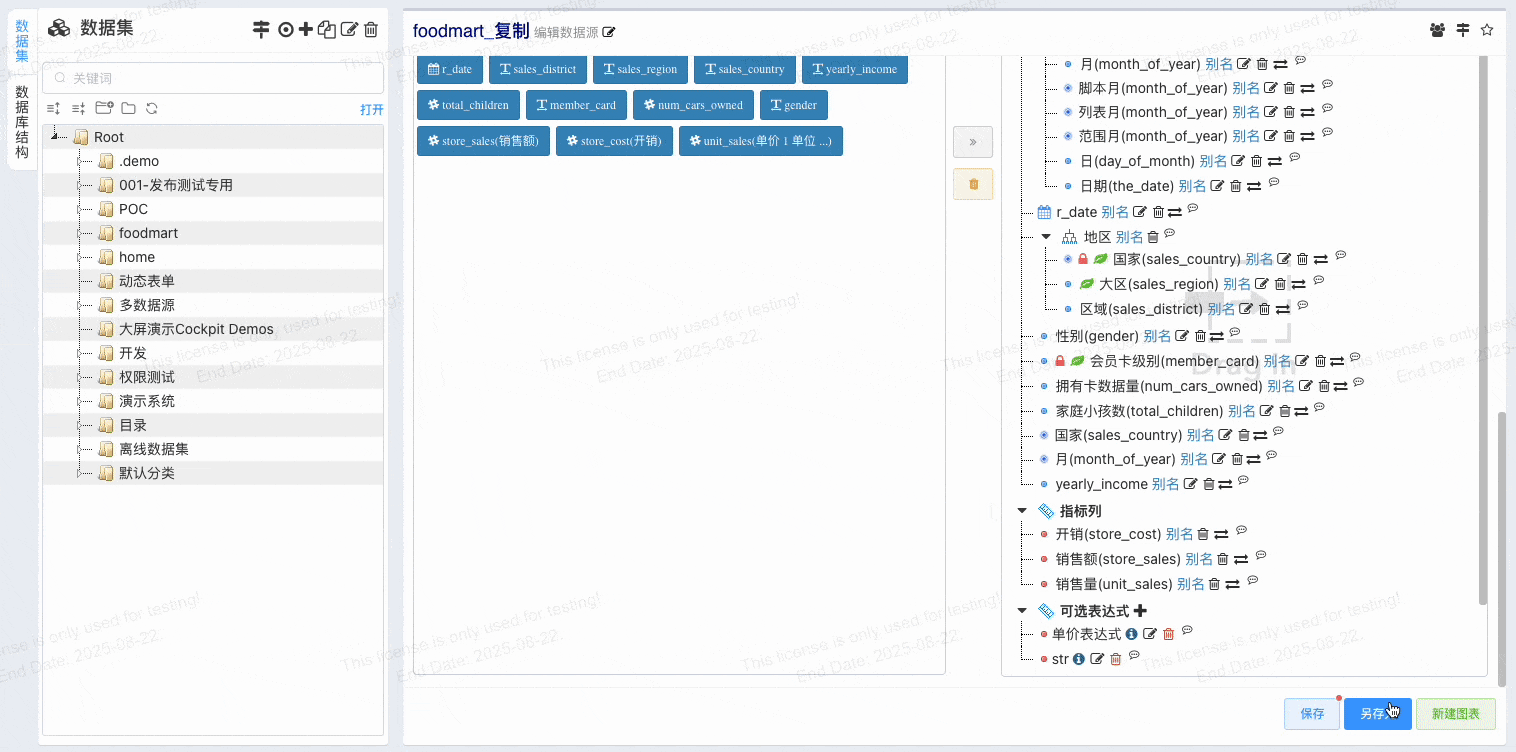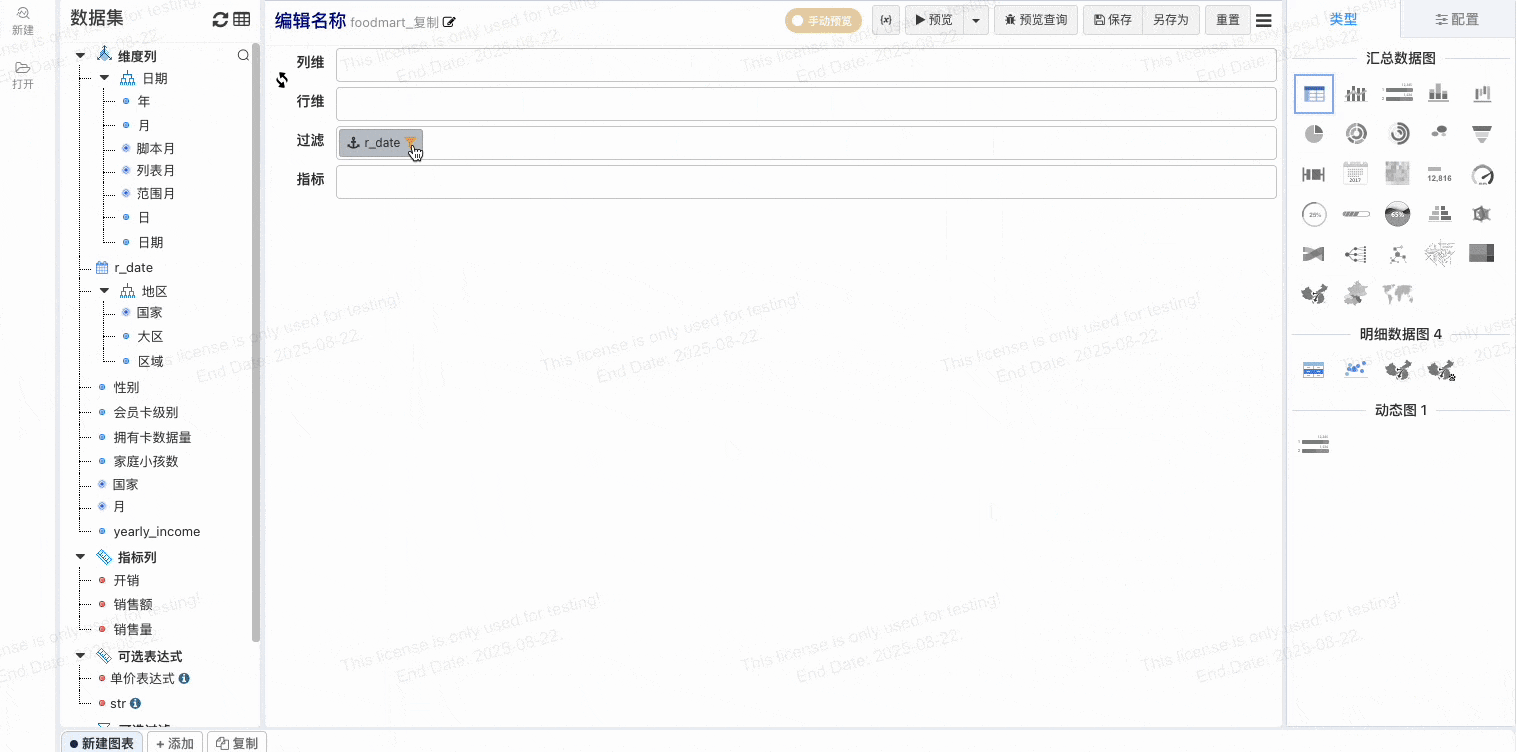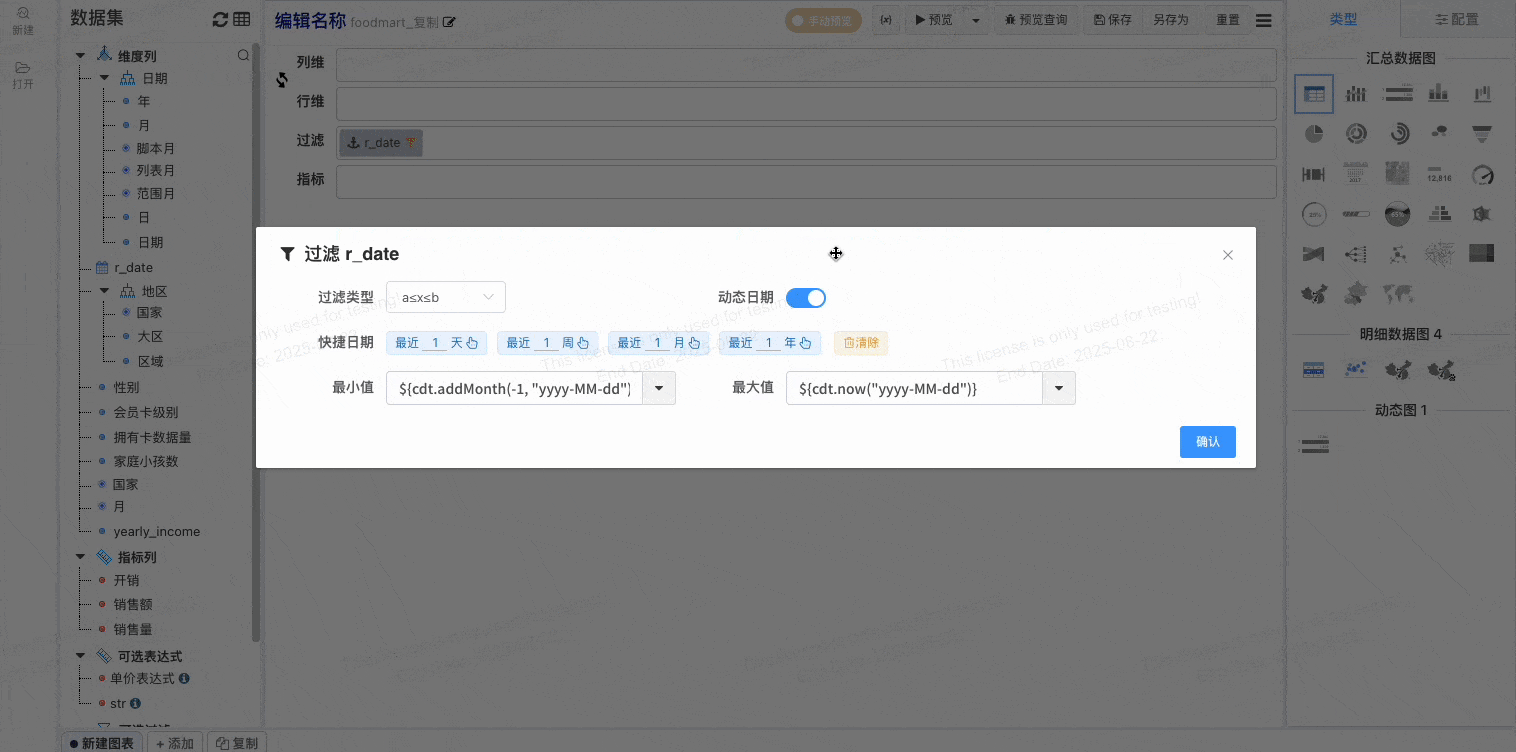
# 维度自动添加到过滤栏v1.14
维度自动添加到过滤栏, 防止大数据集使用忘记添加过滤条件,让业务人员使用起来更加便捷,整体提高系统的稳定性
- 配置维度自动添加到过滤栏
- 设置默认过滤值
# 图表级表达式
是否允许在图表设计阶段,新建表达式,该功能可能与维度、指标列权限冲突,因为通过表达式可以查询不在模型可见范围内的字段,如:引号表达式
# 特殊数据集的查询定义说明
# Kylin Native
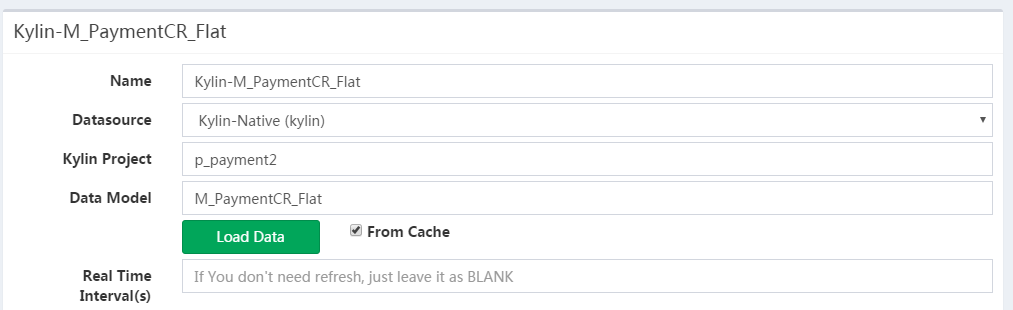
使用Kylin数据源之前需对Kylin基本原理有所了解。
需要填写项, 以及解释如下:
- Kylin Project:对应Kylin本身的Project
- Data Model:对应Kylin Model
# 查询脚本敏感配置1.14
默认场景下为了便于用户能够分析调试、以及更好的理解自助分析动态sql生成原理,在自助分析页面预览查询能够查看查询脚本, 如果您希望控制sql查询脚本的可见性可以通过配置开启数据集查询敏感,限制一些场景的下预览查询按钮是否可见
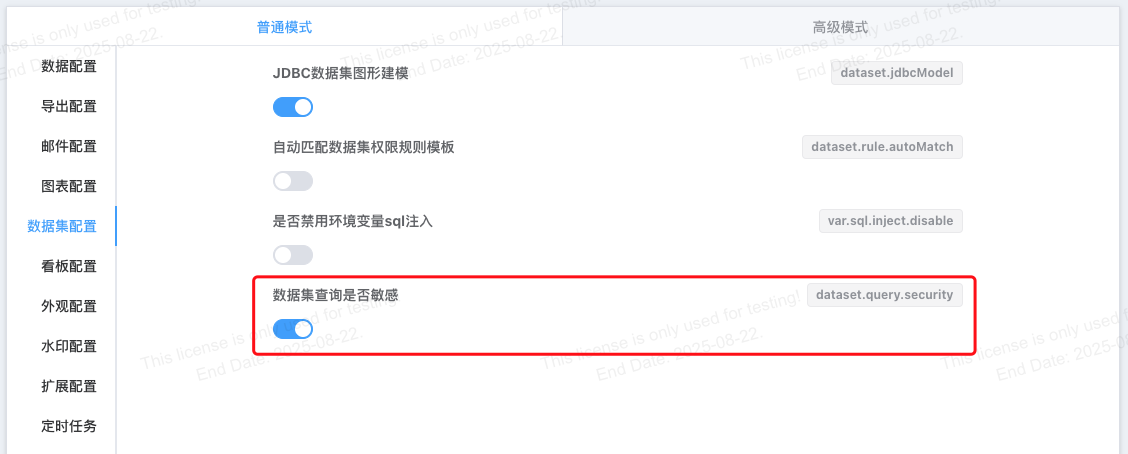
| 是否敏感 | 数据集查询 | 数据集 保存与另存为 | 自助分析 预览查询 | 网格看板 预览查询 |
|---|---|---|---|---|
| 关闭 | 数据源权限 | 可见 | 可见 | 看板编辑权限 |
| 打开 | 数据源权限+数据集编辑权限 | 数据集编辑权限 | 看板编辑权限 |