ChatBI/问数
2025-5-19 About 33 min
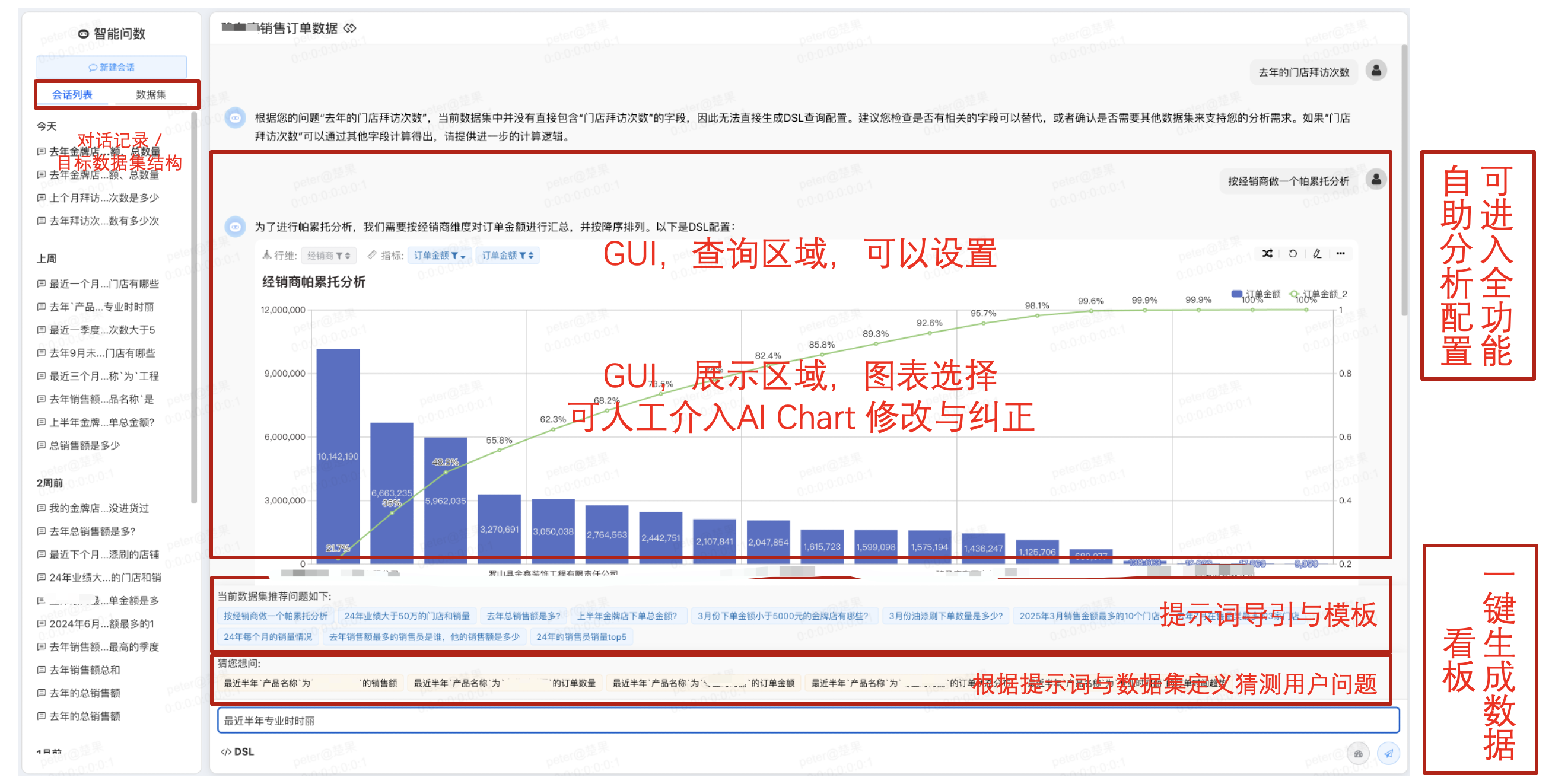
为了进一步降低数据分析的使用门槛,我们引入了智能问数模块,拥抱大模型技术的发展。这一创新使得用户能够通过语音指令实现数据查询与分析操作,而无需进行传统的拖拉拽交互方式来完成数据透视等复杂操作。
借助大模型的自然语言处理技术,用户只需简单地说出他们的数据查询需求或分析意图,系统就能智能解析并将其实时转化为相应的数据操作,如筛选、排序、分组汇总以及数据透视等。
这种方式不仅极大地简化了数据分析流程,还提升了用户体验,让用户能够更加专注于洞察数据背后的价值,而非操作工具本身。无论是对于数据分析新手还是专业人士,智能问数模块都提供了更为便捷、直观的数据探索途径。
注意
当前问数功能处于智能分析的第一阶段,主要支持数据圈选和文本转自助分析配置,尚未涵盖增强分析功能。
这意味着它还不能处理需要多个分析查询才能得出的复杂分析答案,也无法自动生成完整的分析报告。
# 开箱即用&个性化配置
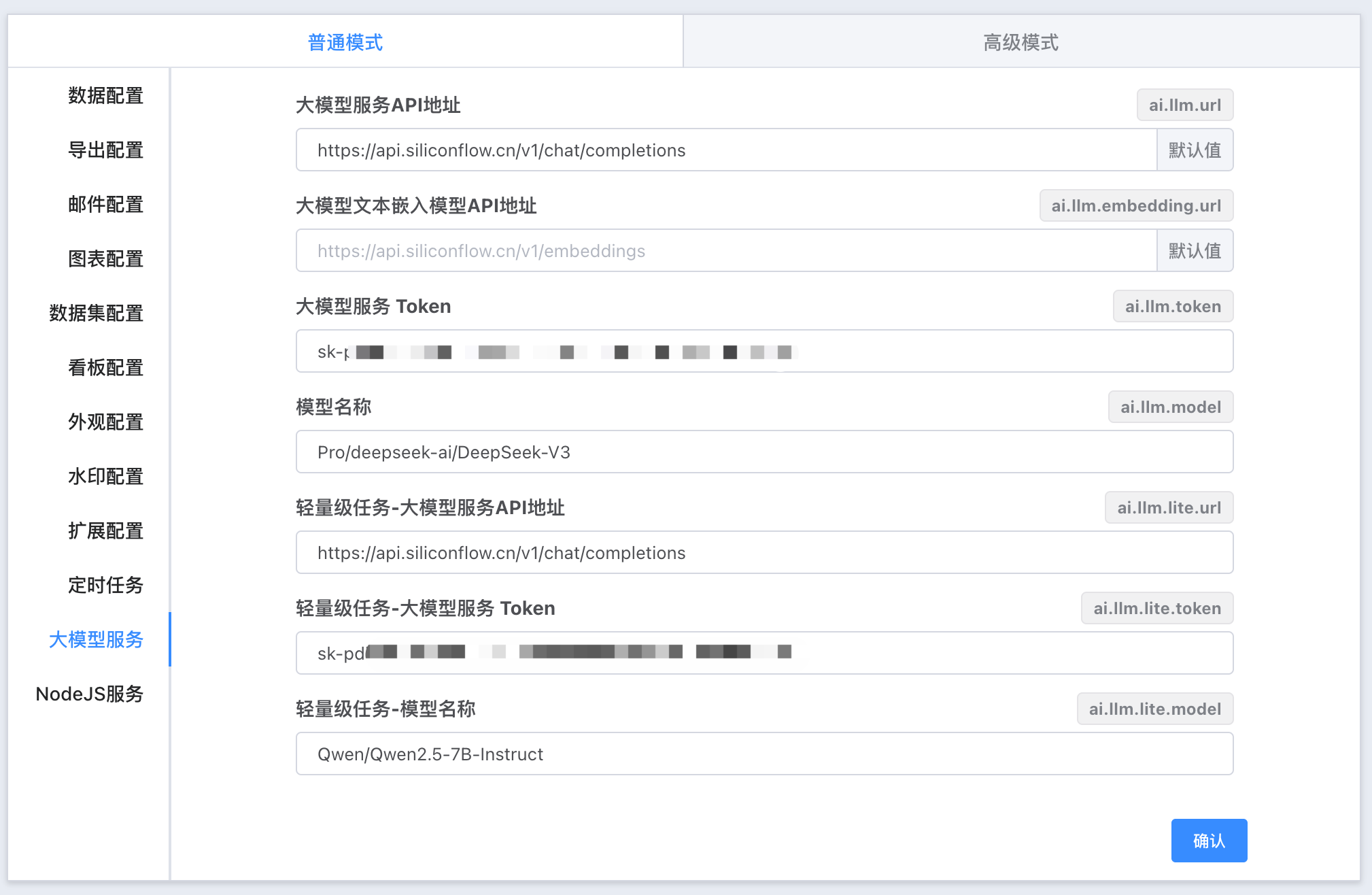
# 大模型服务配置
我们支持对接主流的大模型云服务(如参数量70B以上的模型),同时也兼容自有大模型部署。对于‘猜您想问’这类功能,推荐使用较小参数量的轻量级模型,以有效节省token使用成本并提高响应速度。
以下是一些主流大模型厂商及其API服务地址的信息。请注意,具体的API访问方式、token获取流程及费用等细节可能会根据厂商的政策有所变化,因此建议直接访问各厂商的官方网站或开发者文档以获取最新信息。
- OpenAI (GPT系列)
- 官网: https://openai.com/
- API文档: https://platform.openai.com/docs/api-reference
- Token获取: 需要在官网注册并创建应用后获得API密钥
- Anthropic (Claude系列)
- 官网: https://www.anthropic.com/
- API接入需联系官方或查看其开发者文档获取最新指引。
- 阿里云 (通义千问等)
- 官网: https://www.aliyun.com/product/qianwen
- API文档: 可通过阿里云官网进入相应的API文档页面查找详细信息。
- 百度智能云 (文心大模型系列)
- 官网: https://cloud.baidu.com/product/wenxin.html
- API文档: https://cloud.baidu.com/doc/WENXIN/index.html
- 腾讯云 (混元大模型等)
- 官网: https://cloud.tencent.com/
- 需要登录腾讯云账号后,在产品服务中找到相关的大模型服务进行API调用。
- 华为云 (盘古大模型等)
- 官网: https://www.huaweicloud.com/
- 类似地,需登录华为云账号后访问相应服务页面。
- DeepSeek
- 官网: https://www.deepseek.com/
- 具体API服务和token获取方式请参考其官方提供的指南。
对于轻量级大模型用于“猜您想问”功能,可以考虑使用参数较少的模型如ERNIE Lite或类似的小型化版本,这些通常会更加经济高效,适合处理实时性要求高但计算资源消耗相对较低的任务。
为了确保信息准确无误,请直接访问上述链接或查阅各厂商最新的官方资料。
# 查询任务模型
ai.llm.url=https://api.siliconflow.cn/v1/chat/completions
ai.llm.token=sk-***
ai.llm.model=Qwen/Qwen2.5-72B-Instruct-128K
# 阿里
#ai.llm.url=https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions
#ai.llm.token=sk-***
#ai.llm.model=qwen-plus-latest
# deepseek
#ai.llm.url=https://api.deepseek.com/chat/completions
#ai.llm.token=sk-***
#ai.llm.model=deepseek-reasoner
# 轻量级任务模型
#ai.llm.lite.url=https://api.siliconflow.cn/v1/chat/completions
#ai.llm.lite.token=sk-***
#ai.llm.lite.model=Qwen/Qwen2.5-7B-Instruct
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
大模型相关配置,可以在 管理 -> 系统配置 -> 大模型服务 中配置
# 快速启动
- 快速启动:数据集无需额外配置,开箱即用
- 在BI系统中,历史数据集无需任何额外配置即可直接作为问数的数据集使用,简化了数据准备流程,让用户能够立即开始进行数据分析
0配置冷启动问数数据集配置建议
当我们选择问数的数据集对象之后,系统会把数据集维度指标字段告诉大模型,只有在大模型理解数据集字段的含义之后才能生成正确的配置因此
为了提升问数数据集的准确性和效果,建议采取以下措施:
- 优化字段命名:确保字段名称清晰易懂,避免复杂或模糊的表述,以便模型更好地理解和处理。
- 提供详细字段描述:为每个字段添加详细的描述信息,帮助模型理解其含义和用途。
- 丰富知识库信息:在知识库管理中添加和编辑当前数据集的额外知识,帮助大模型更好地理解用户意图和数据背景。
- 通过这些步骤,可以显著提高数据集的质量和问数功能的准确性。
# 个性化设置
数据集问数相关配置
尽管BI系统支持开箱即用的历史数据集用于问数功能,但对于某些问数效果不理想的数据集,进行相应的个性化配置可以显著提升大模型对数据集的理解和用户提问的准确性。
通过个性化配置,您可以优化数据结构、定义关键指标以及调整参数设置,确保更精准的数据分析结果和更符合预期的响应,从而改善整体问数体验和效果。
这种定制化调整特别适用于复杂或特定领域的数据集,有助于克服通用处理方式的局限性。
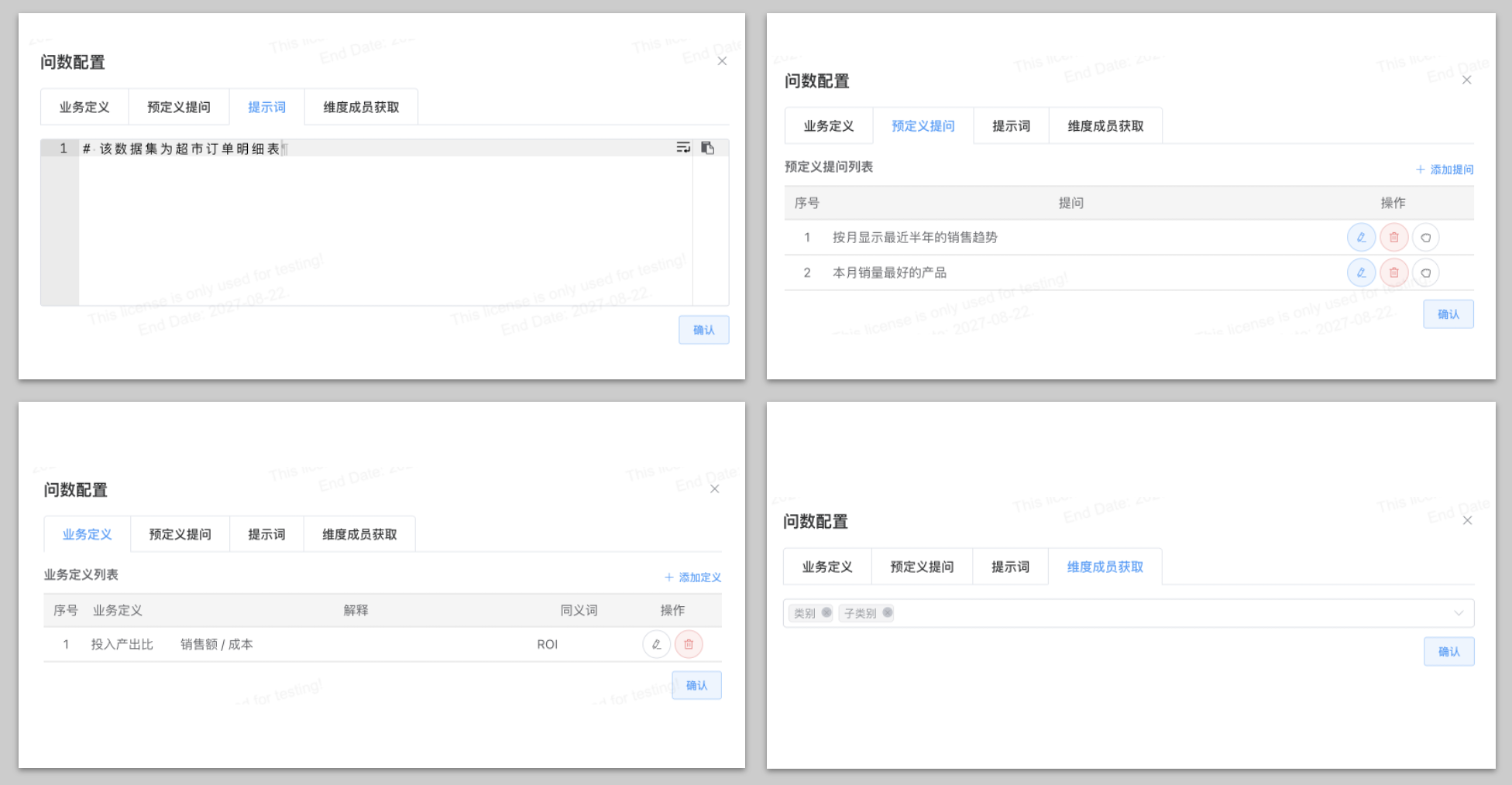
- 业务定义: 对于一些专有名词或者口头用语,通过近义词和自然语言的解释,加强大模型对口语化提问及更深的业务场景的理解。
- 预设问题: 预定义提问,即用户引导问题,用来设定用户在某一主题下查用的一些问题模板,便于对用户提问之前进行引导
- 提示词设定: 用户可以在提示词中嵌入特定提示词,与大模型交互,引导模型更好的理解业务场景和生成自定义的内容
- 维度成员获取定义等: 将所选维度数据字典导入,维度值在搜索时可以被联想出来
# 选择对话数据集
- 从顶部菜单栏,点击问数机器人图标进入问数模块
- 选择问数对象数据集
- 左边栏会显示当前对象数据集的维度、指标信息
- 开始问数
# 图表生成
典型问数问题:
- 2024年6月销售金额最多的10个门店
- 去年7月在售品类最多的3家门店
- 给我3家24年卖过书桌的门店。
- 给我3家24年没有卖过书桌但销量最高的门店
- 去年销售额最多的销售员是谁,他的销售额是多少
- 24年每个月的销量情况
- 24年的销售员销量top5
- 24年业绩大于50万的门店和销量
- 去年同比销售下降、上升的产品有哪些
- 按产品大类做销售额帕累托分析
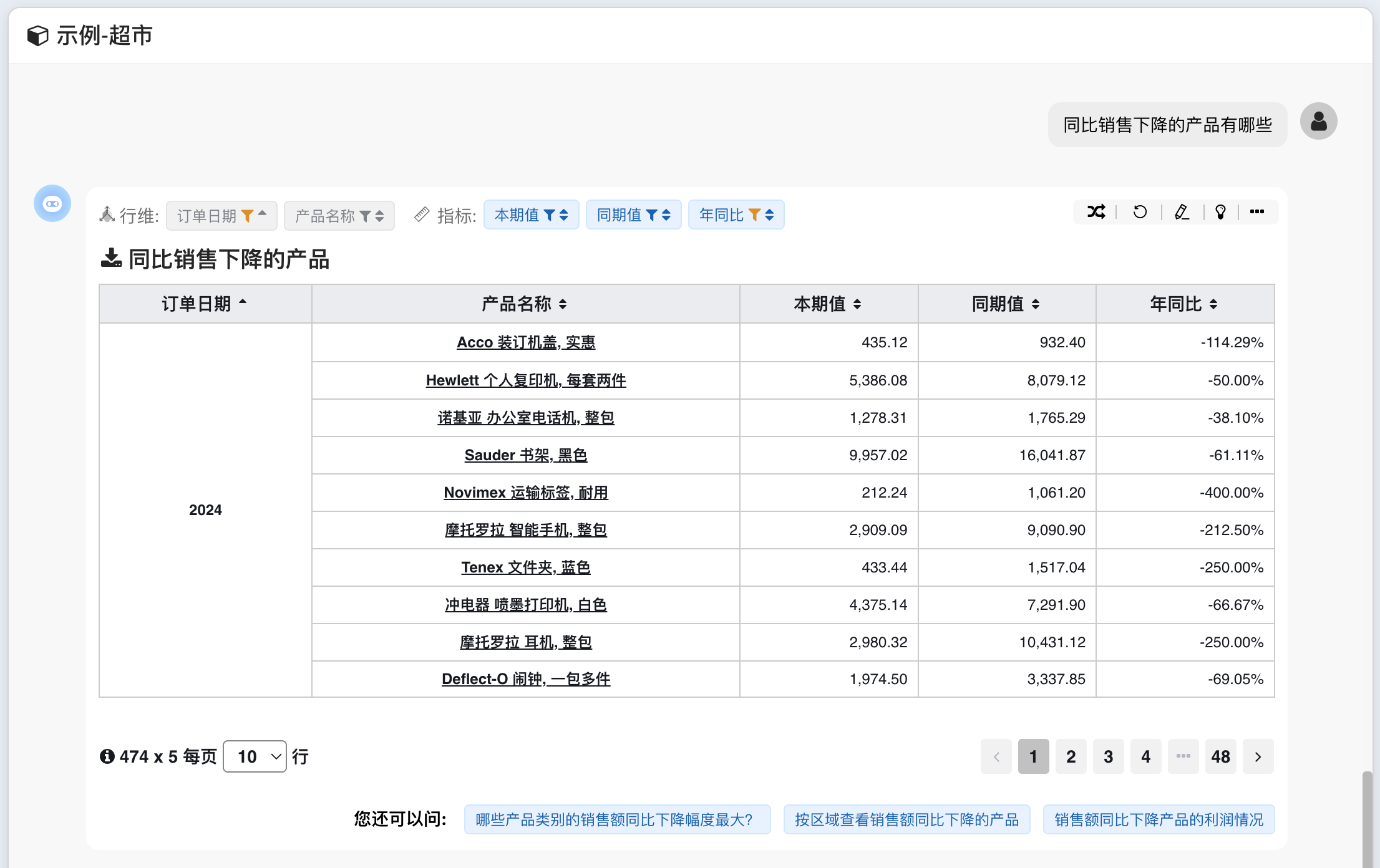
支持交叉表、柱线图、饼图等多种图表类型
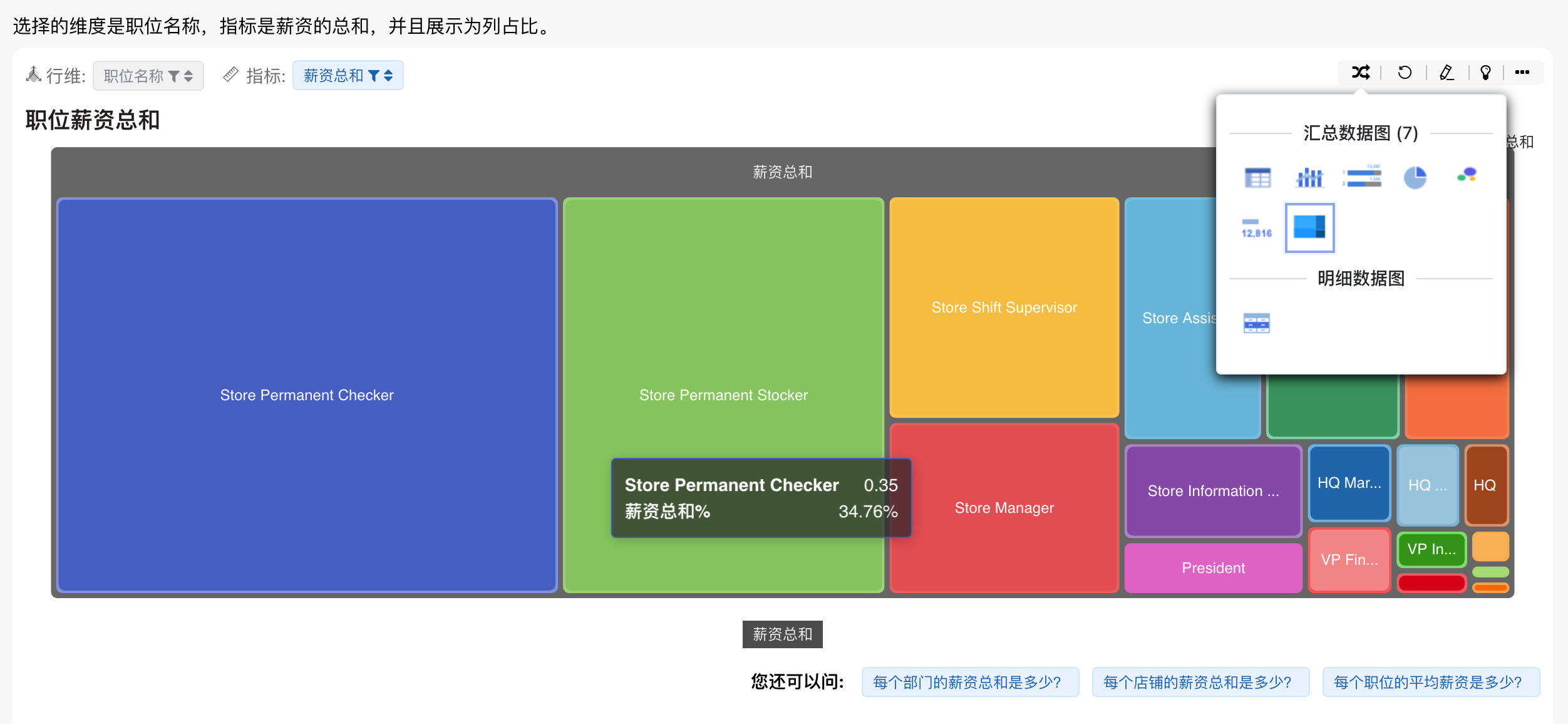
# SQL/DSL查询
支持可调试的AIChart DSL和SQL查看,让用户能够详细检查并优化图表生成逻辑与数据查询语句。
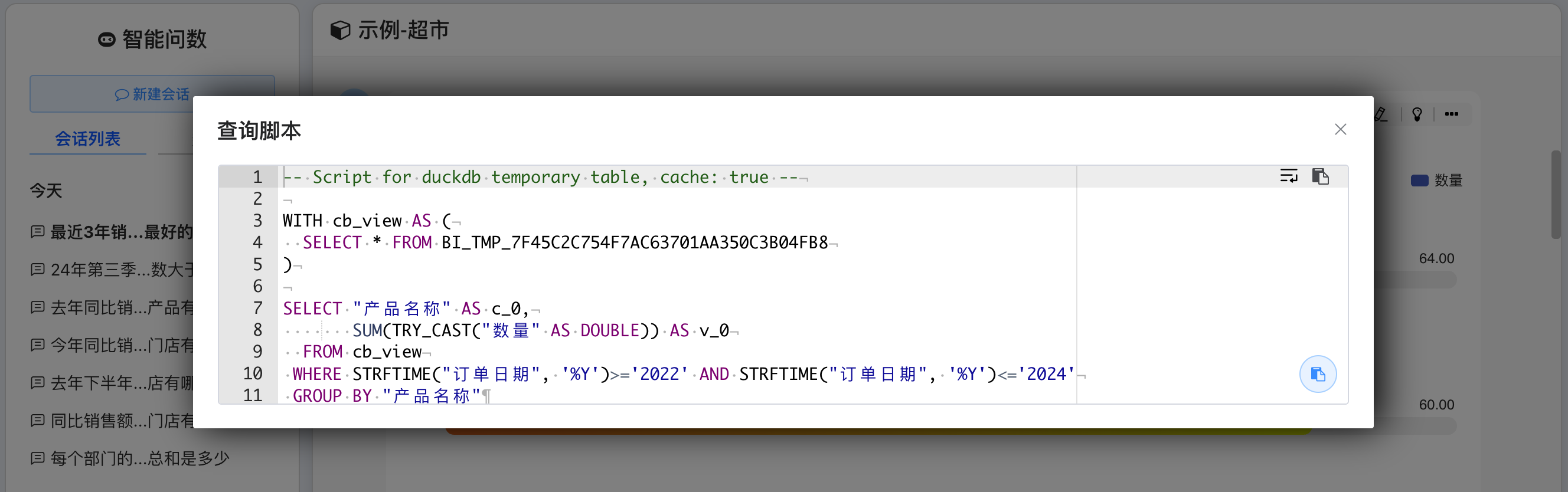
# AI生成配置修改
当AI生成的查询结果不符合预期时,用户可以便捷地介入并修改,包括调整排序、应用维度过滤或指标过滤等操作,确保查询结果精确匹配需求。这种可干预修正的能力让用户能够灵活优化AI建议的查询条件,提升数据检索和分析的准确性与适用性。
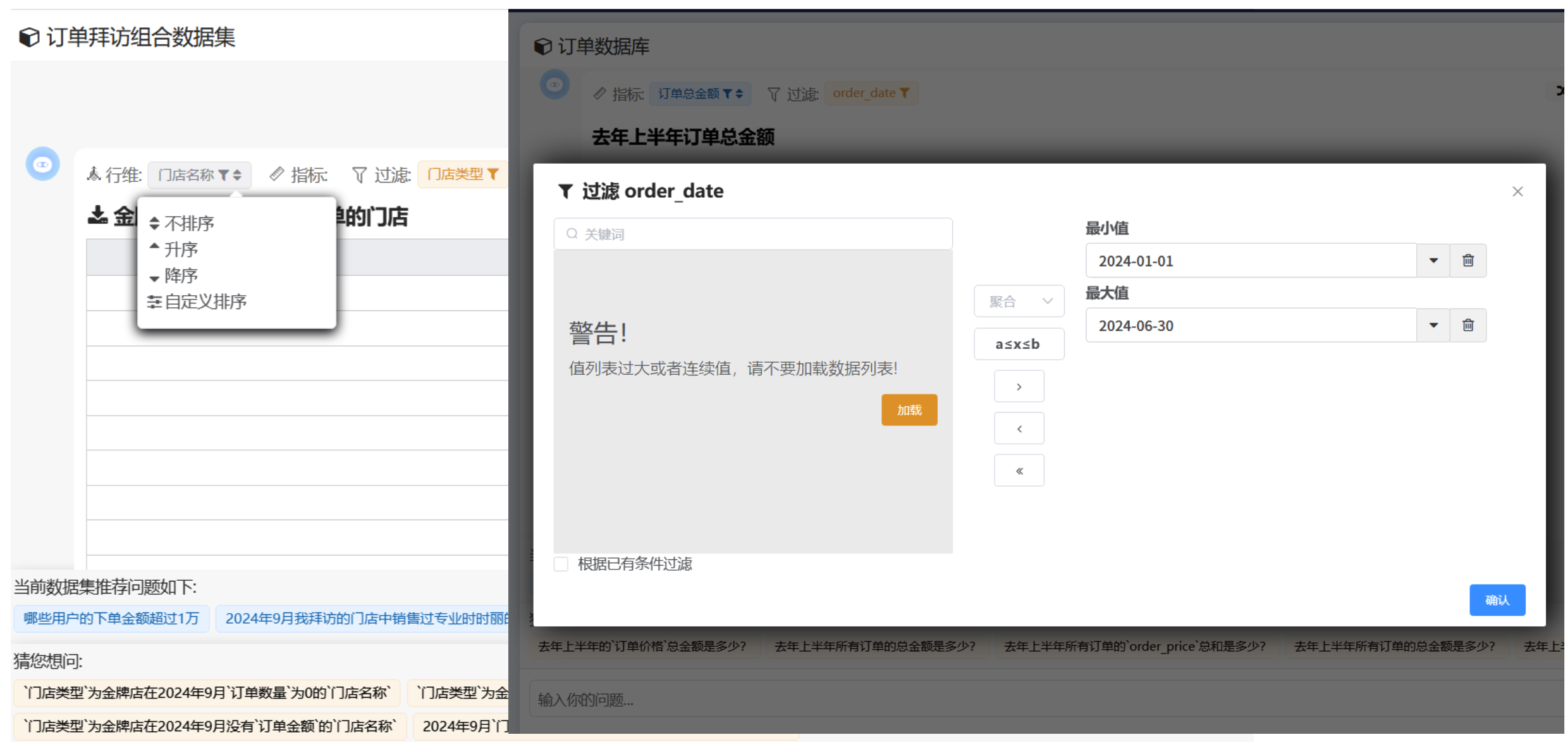
# 切换至高级分析模式
如果您希望使用完整自助分析的配置功能,可以切换至高级分析模式。这种模式专为那些需要更深入、更灵活的数据探索和分析的用户设计,提供了增强的功能集来支持复杂的数据操作和分析任务。

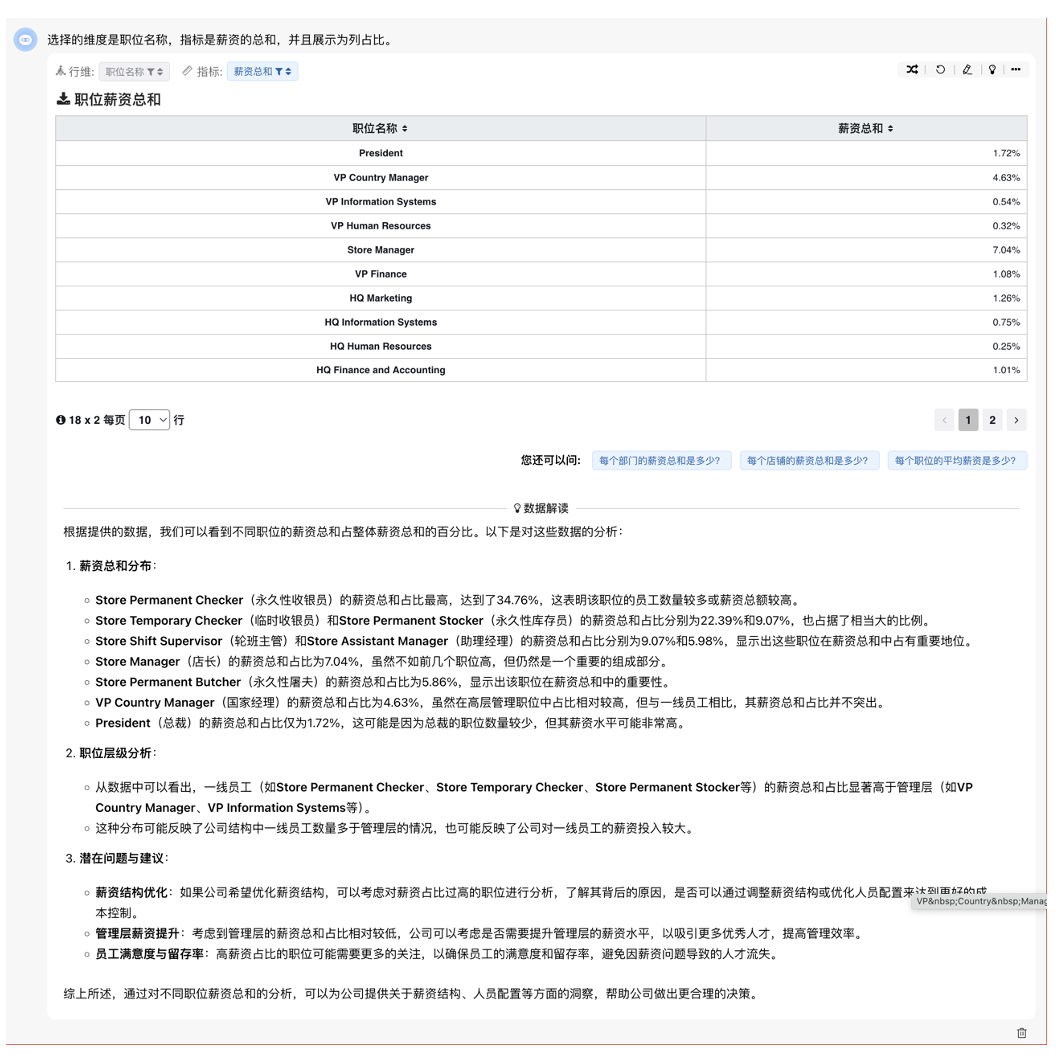
# 数据解读
在使用数据解读功能时,默认情况下查询结果不会直接传递给大模型。如果需要大模型帮助解读和分析数据,您可以主动点击“数据解读”按钮以发起请求。
Context长度限制
当前所有大模型都有内容长度(context)的限制。这意味着当查询结果的数据量过大时,尝试发送这些数据给大模型进行解读可能会失败

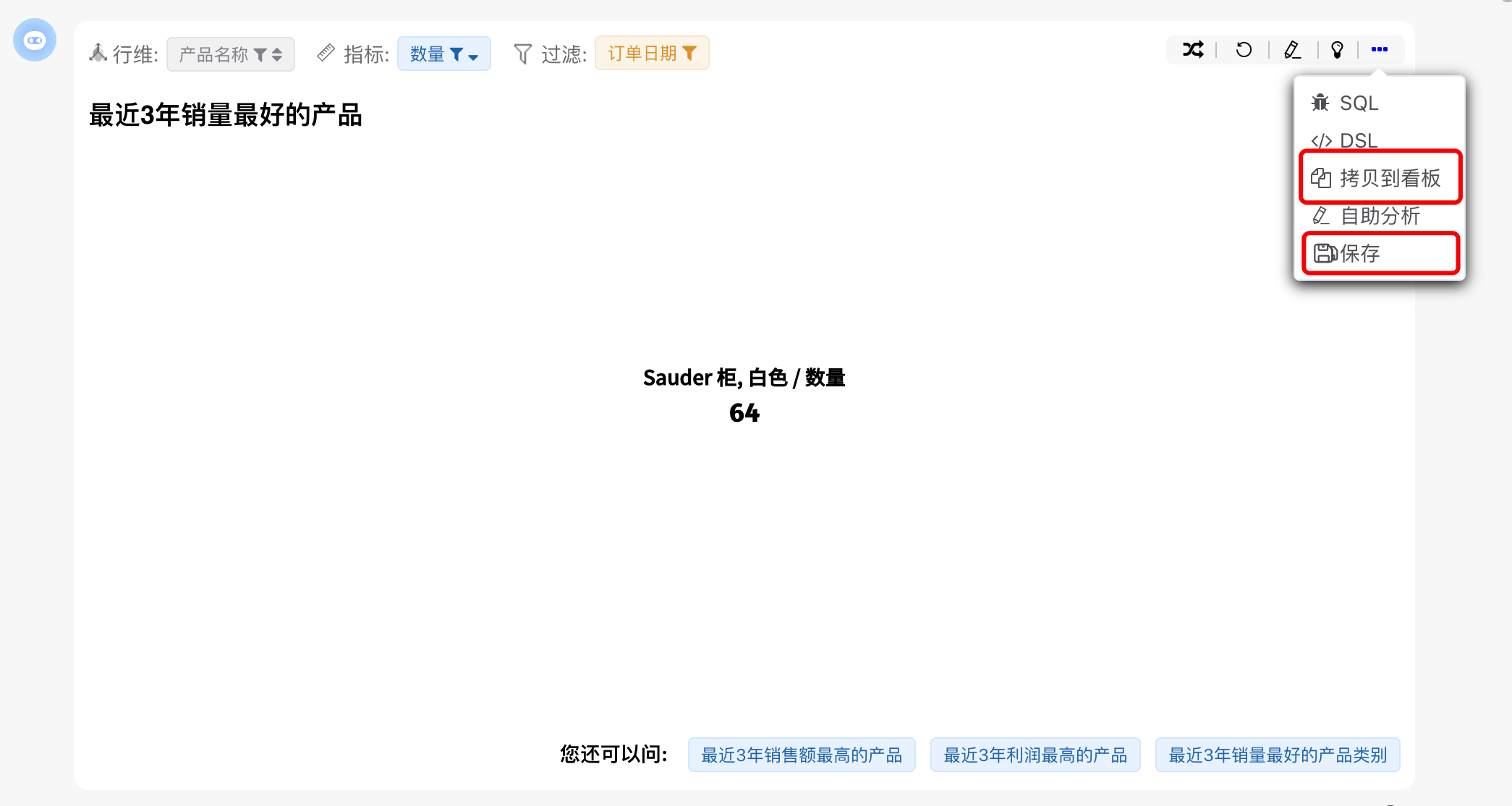
# 保存图表
通过AI图表保存功能,用户可以将生成的图表直接保存到自助分析模块中,或拷贝到看板,实现与BI分析平台各功能模块的无缝对接。 这一特性不仅让数据分析结果得以灵活应用和长期跟踪,还打破了单一会话输出的限制,支持更深入、连续的数据探索和展示。
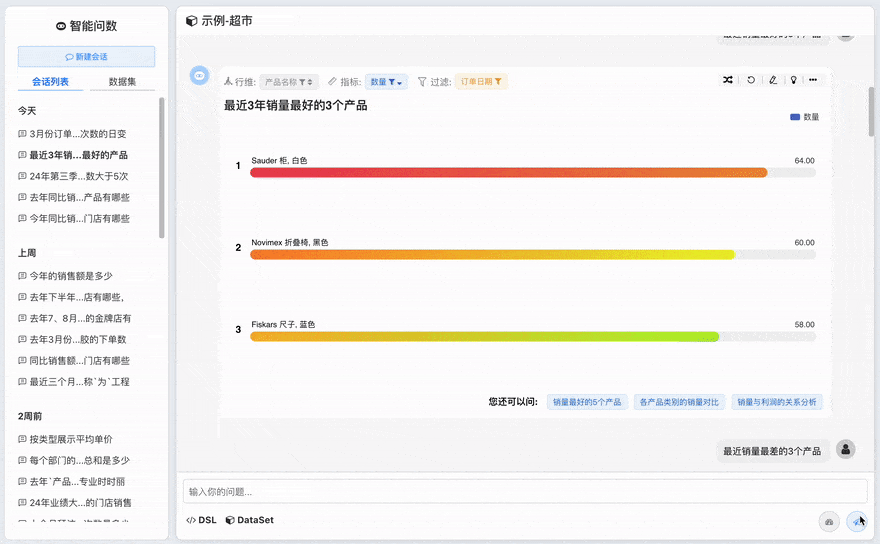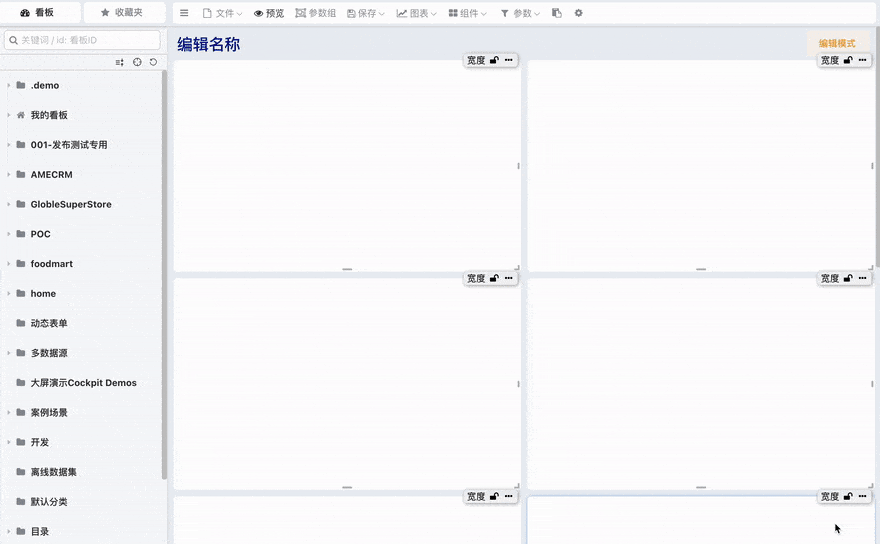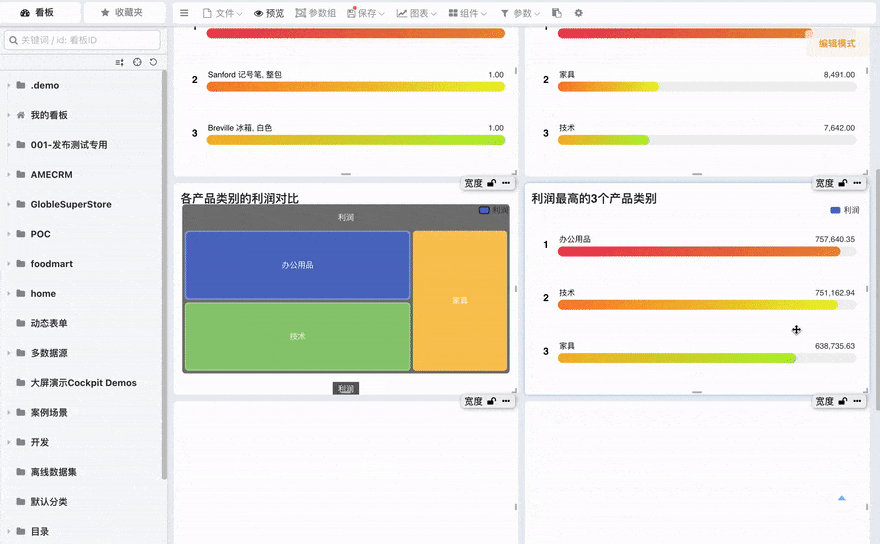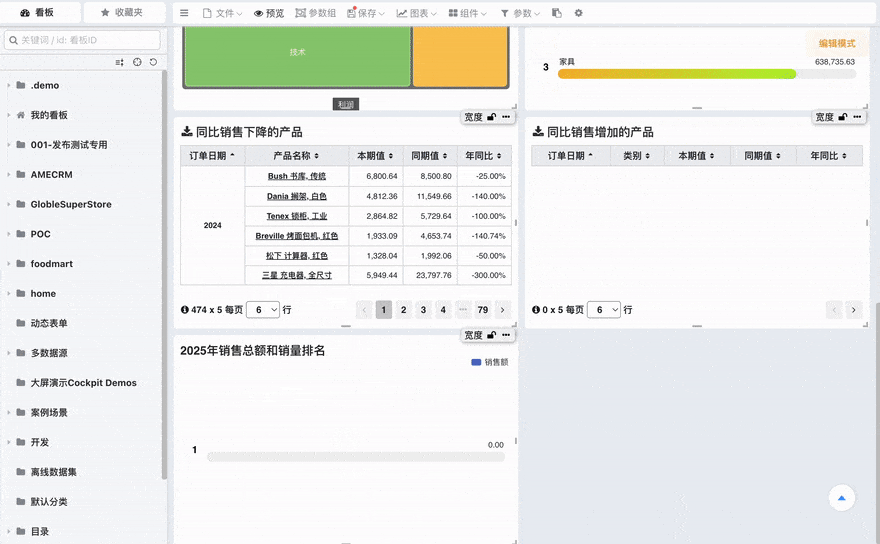
# 一键生成看板
一键生成看板功能可将对话中的图表快速保存并集成到看板中。
# 个性化设置
数据集问数相关配置
尽管BI系统支持开箱即用的历史数据集用于问数功能,但对于某些问数效果不理想的数据集,进行相应的个性化配置可以显著提升大模型对数据集的理解和用户提问的准确性。
通过个性化配置,您可以优化数据结构、定义关键指标以及调整参数设置,确保更精准的数据分析结果和更符合预期的响应,从而改善整体问数体验和效果。
这种定制化调整特别适用于复杂或特定领域的数据集,有助于克服通用处理方式的局限性。
# 业务定义
对于一些专有名词或者口头用语,通过近义词和自然语言的解释,加强大模型对口语化提问及更深的业务场景的理解。
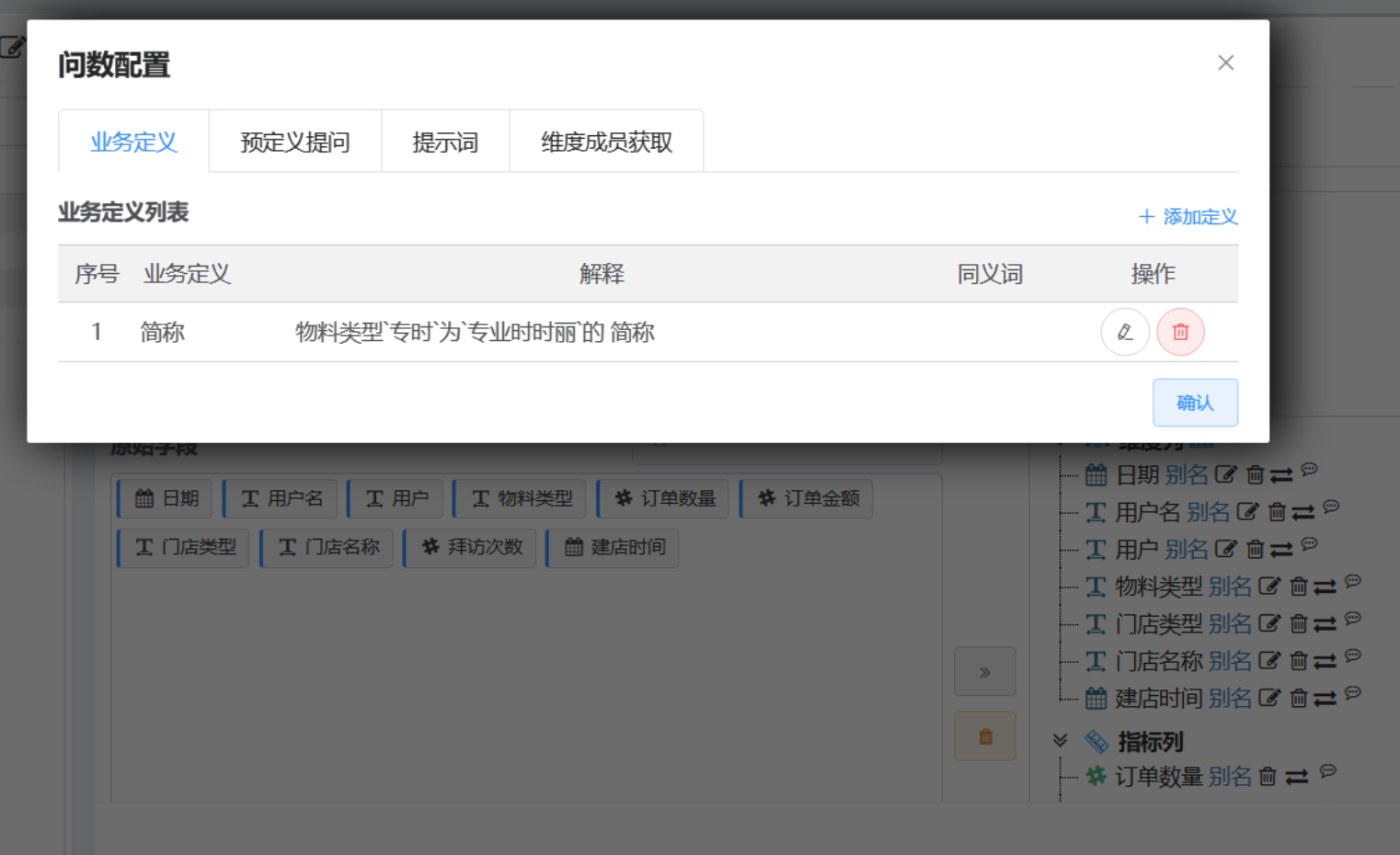
# 预设问题
预定义提问,即用户引导问题,用来设定用户在某一主题下查用的一些问题模板,便于对用户提问之前进行引导
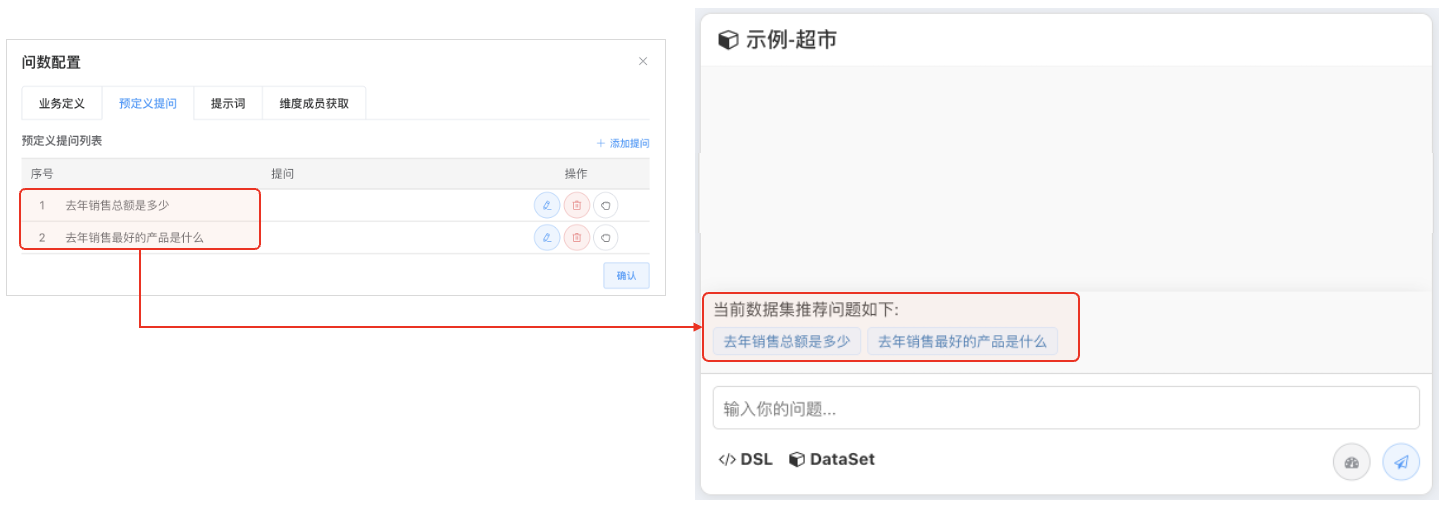
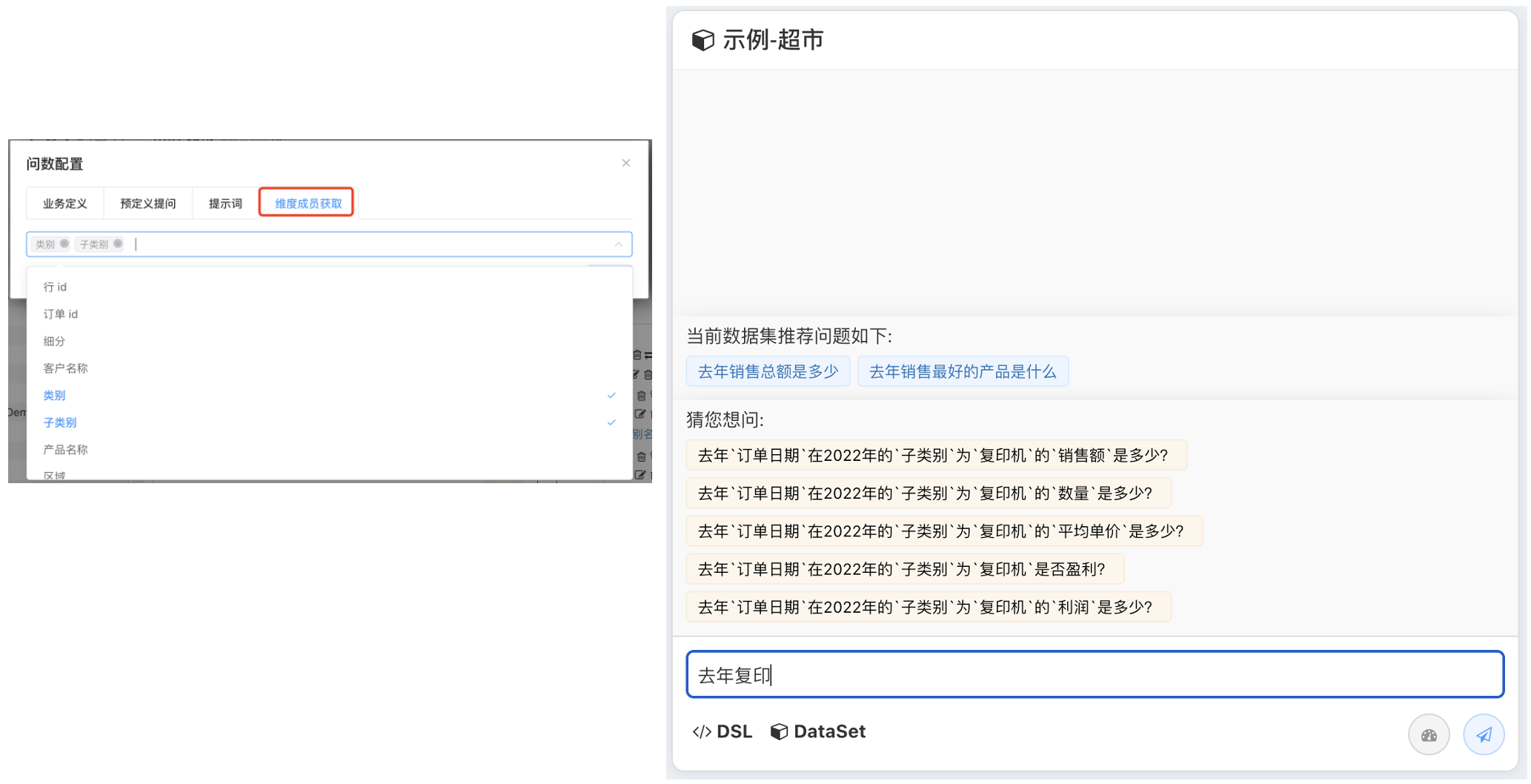
# 猜您想问, 让大模型知道你字段内容
为了让大模型更好地理解您的数据集字段内容,并在用户提问时即使输入不完整或存在错误也能准确猜测用户的意图,可以采取以下措施:
维度成员获取定义:将所选维度的数据字典导入系统。例如,对于“产品”这个字段,您可以导入包含所有产品的详细列表。这样,在用户进行搜索或提问时,系统可以根据预导入的数据字典联想出相关的维度值(即具体的产品名称)。这不仅提高了查询的准确性,还增强了用户体验。
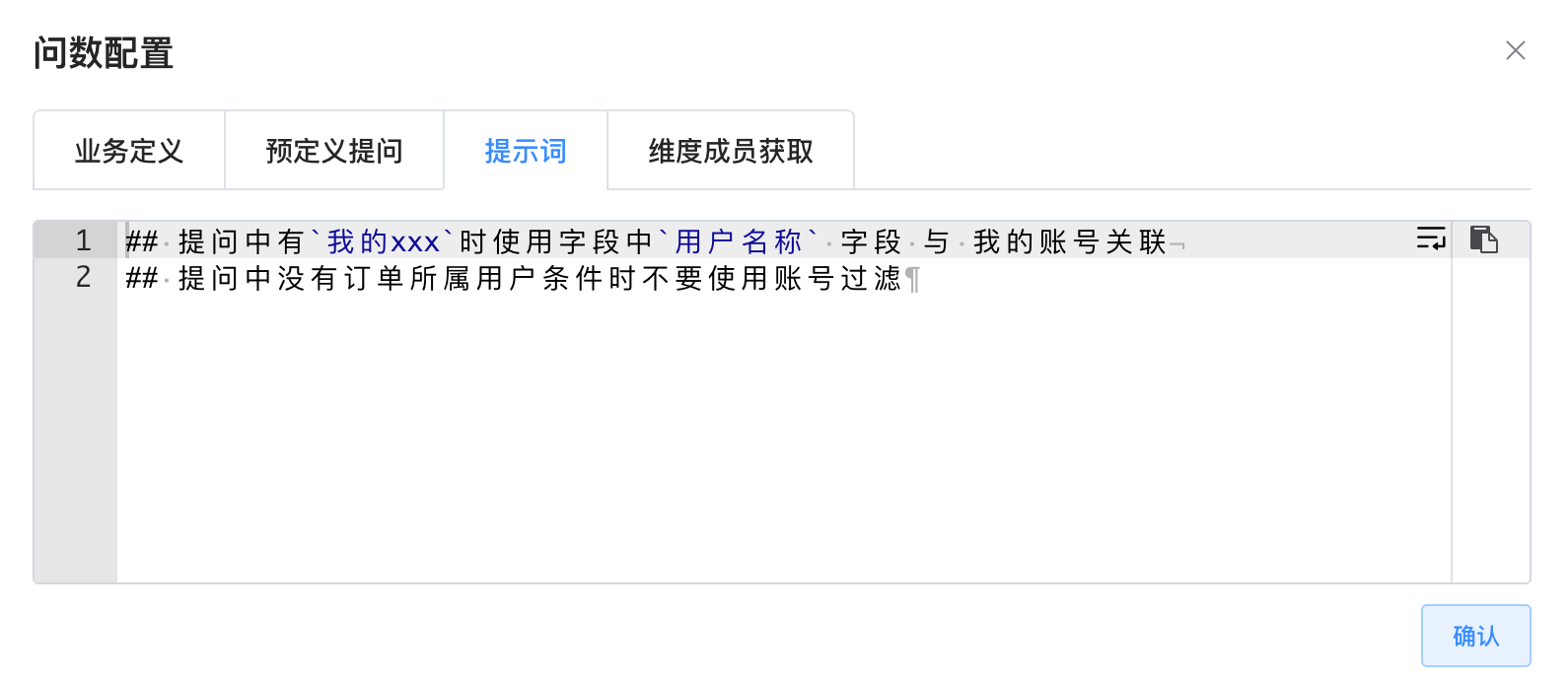
# 提示词嵌入
为了使大模型更好地理解特定的业务场景并生成符合用户需求的自定义内容,用户可以在提示词中嵌入特定的关键词或短语。 这种方法被称为“提示词嵌入”,它通过向模型提供更精确的上下文信息来引导其输出结果,从而提高交互的相关性和准确性。
# 检索增强生成(RAG)知识库管理
对于复杂的分析指标和业务场景,如:帕累托分析、同比环比、反向过滤等,通过结构化存储名称、描述和DSL预定义,降低使用门槛,确保同类报表一致性,减少试错成本。
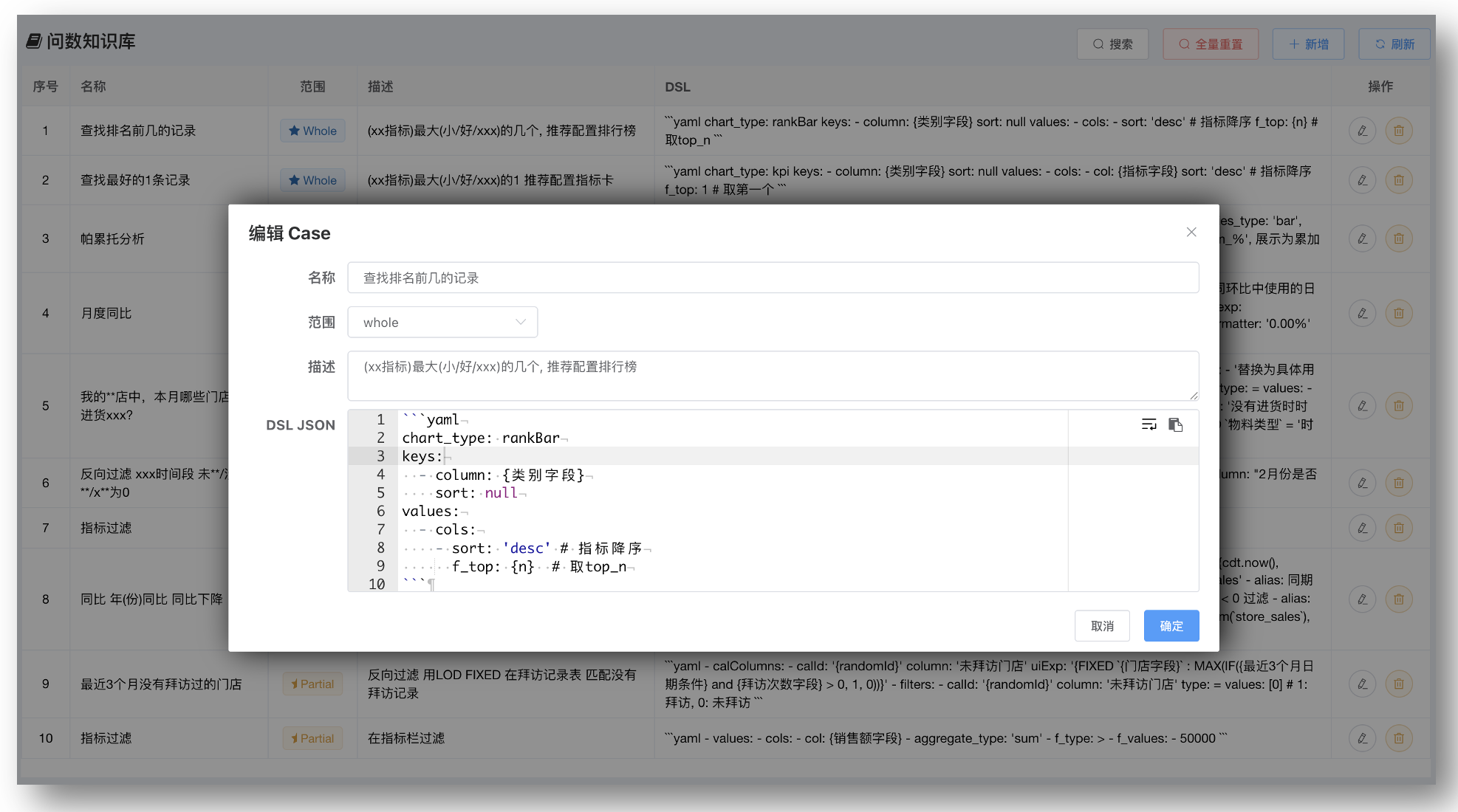
- DSL JSON 案例定义可以参考前端SDK工具包中 Business Object 中关于配置的解释
- 建议使用YAML描述配置,相对JSON更加精简