表达式
2021-10-10 About 46 min
在报表使用过程当中,不可避免的要使用函数及表达式实现一些数据的计算,在Report当中,很多地方都支持编写表达式,比如最典型的我们可以将单元格类型改为“表达式”,这样就可以在下面的表达式编辑器里输入相应的表达式与函数
Tips
- 复杂报表的计算引擎与多维分析的引擎为两套完全不同的引擎,表达式与多维分析数据集中的汇总表达式完全不一样
- 复杂报表的表达式为是一套自定义语法,可能部分语法与其他语音类似,比如Javascript,但绝对不能通用
# 基本语法
与一般的编程语言类似,表达式也有一些基本的数据类型,比如数字、字符串等,如下表所示:
Note
关键词区分大小写,如单元格坐标A1,and, or, if, else, case等
| 表达式类型 | 描述 | 示例 |
|---|---|---|
| 数字 | 可以是一个整数,也可以是一个小数 | 1、123、0.121331,这些都是合法的数字 |
| 字符串 | 字符串需要用单引号或双引号包裹 | 'ureport2'、"UReport2"、‘UReport2教程’,这些都是合法的字符串 |
| 布尔值 | 布尔值表示是或否 | 布尔就两个:true 和 false |
上述的有三种基本的数据类型,可以单独使用,也可以用“+”、"-"、"*"、"/"、"%"连接,进行组合运算,如下表所示:
| 操作符 | 描述 | 示例 |
|---|---|---|
| + | 求两个数的和,或者是连接两个值 | 21+31,这就表示求这两个数的和,结果就是 52,“值:”+331则表示连接两个值,其结果就是“值:331” |
| - | 求两个数差 | 21 - 31,这就表示求这两个数的差,结果就是-10 |
| * | 求两个数的乘积 | 3*6,结果就是18 |
| / | 求两个数除的结果 | 6/3,结果就是2,如果除不尽,则会保留8位小数 |
| % | 求两个数除的余值 | 5%3,结果是2;6%2结果是0 |
| and/or | 条件关联符号 | A1 > 10 or B1 == 1 and A1 < 20 |
# 变量定义
通过var定义变量,变量值可以为常数后者其他表达式
var a = 1;
var b = fd1.sum(store_cost)
if (b >0) {
b
}
1
2
3
4
5
6
2
3
4
5
6
# 三元表达式
基本所有的语言都支持三元表达式判断,它的特点是简洁明晰,可以用最少的代码进行条件判断,Report中的三元表达式语法结构如下:
ifCondition ? expr : expr
和普通的三元表达式一样,它的第一部分是条件部分,条件部分可以有多个条件(用and或or连接),“?”后面是条件满足后执行并返回的表达式部分,“:”后面则是条件不满足时执行返回的表达式部分。
| 三元表达式示例 | 说明 |
|---|---|
| A1>1000 ? "正常值" : "低值" | 表达式计算时,先取到A1单元格的值,判断值是否大于1000,如果是返回“正常值”字符串,否则返回“低值”字符串 |
| A1>1000 and A1<20000 ? "正常值" : "修正值:"+(A1+100) | 条件部分,判断A1值是否大于1000 且小于20000,如果是返回"正常值",否则返回字符串”修正值“与A1值加100后结果连接的值,如果A1是2000,那么就返回”修正值:2100“ |
# if判断
if判断表达式则一个if条件判断部分加若干个可选的elseif 条件判断部分,最后再加一个可选的else部分构成,语法结构类似java或javascript
提供代码提示snippet自动填写模板, 模板填入之后可以使用tab键在需要变更的地方跳动光标方便输入
// 判断A1单元格的值是不是大于1000,如果是返回”正常值“字符串,否则什么都不做
if(A1>1000){
return "正常值"
}
1
2
3
4
2
3
4
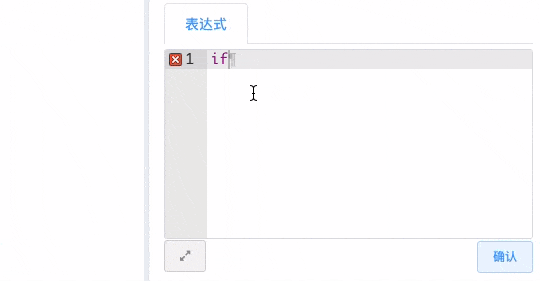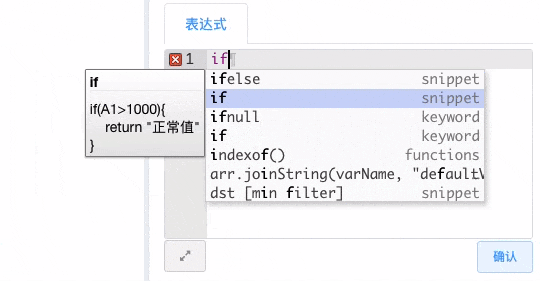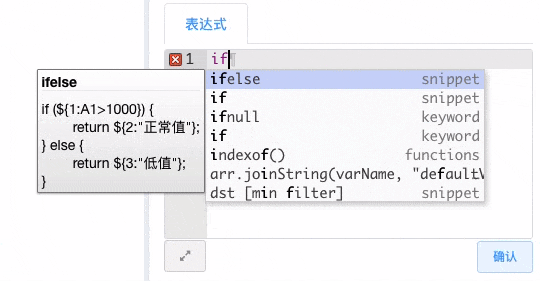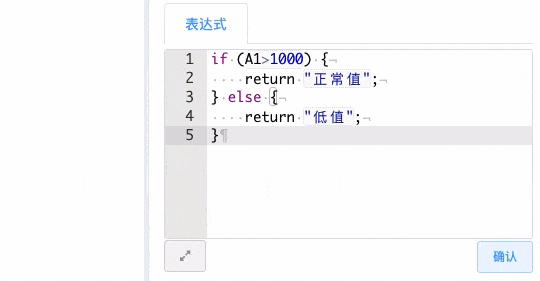
// 判断 A1 单元格的值是不是大于1000,如果是返回”正常值“字符串,否则返回”低值“字符串。
if(A1>1000){
return "正常值"
}else{
"低值";
}
1
2
3
4
5
6
2
3
4
5
6
Tips
这里需要注意的是,在if表达式中,return 关键字是可选的,同是行尾添加';'也是可选的,这主要是为了照顾一些 java 及 javascript 程序的习惯
// 在这个例子当中,条件部分添加了多个组合条件,同时 else if 多重判断
if (A1>1000 and A1<20000) {
return "正常值:"+A1
} else if (A1>20000 and A1<40000) {
return "超高值"
} else {
"低值"
}
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
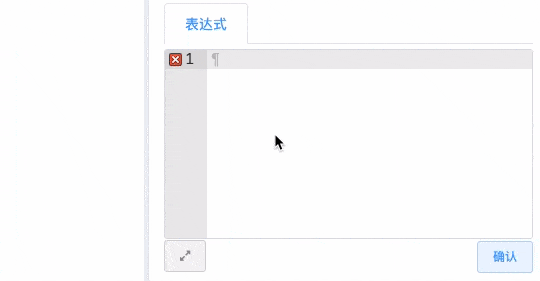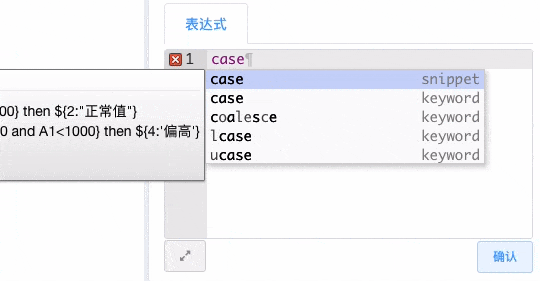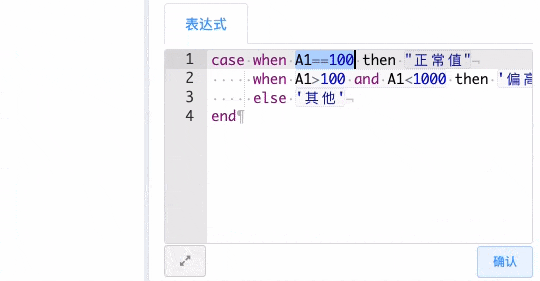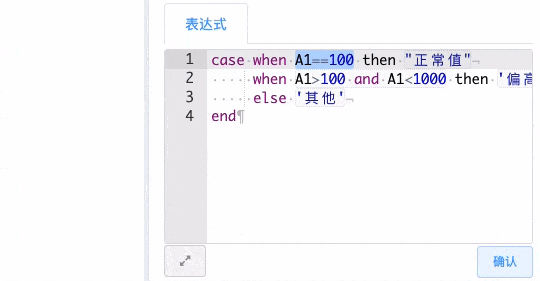
# case判断
case 判断与sql语法一致
case
when condition then exp
(when condition then exp)*
(else exp)?
end
1
2
3
4
5
2
3
4
5
提供代码提示snippet自动填写模板, 模板填入之后可以使用tab键在需要变更的地方跳动光标方便输入
# 单元格引用
在报表当中,大多数的计算都是针对单元格或与单元格有关,因为报表中单元格多数都与数据绑定,而数据往往又是多条, 所以计算后的报表一个单元格会产生多个,这样对于单元格的引用就变的比较复杂。
# 同行/同列引用唯一值
Tips
在 UReport2 报表引擎中,引用的目标单元格是相对当前单元格来进行计算的,引用方法就是直接在表达式里书写单元格名称,比如引用 A1 单元格,就直接写 A1 即可,如下面的例子:

在上图当中,我们在 D1 单元格中输入表达式 A1
当前单元格为: D1, 目标单元格为A1
这就表示,在 D1 单元格里填入相对当前 D1 单元格的 A1 单元格的值,运行后的效果如下:
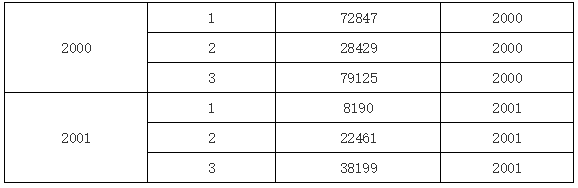
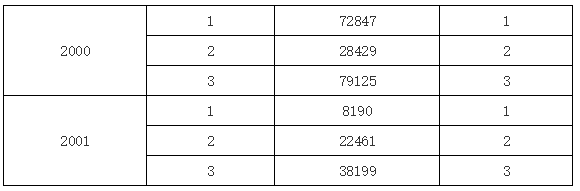
可以看到,因为 D1 是 A1 的子格,A1 单元格绑定的数据就是分组结构,根据当前 D1 单元格的位置,就产生的上图所示的结果。如果在 D1 单元格中输入 B1,那么运行后的效果又是下图的样子:
同样,如果在 D1 中输入表达式 C1,那么运行后将会在每个 D1 单元格中填入与 D1 单元格位于同一行的 C1 单元格的值,运行结果这里就不再贴出来了。
同行同列父格单个值
通过上面的例子我们可以看到,某个单元格的表达式引用目标单元格,首先判断的是目标单元格与其所在单元格是否位于同一行或列,如果是则直接取对应行或列上目标单元格的值。
# 同行/同列引用多个值

因为 C1 是 C2 的上父格,所以将直接取与其位于同一列的上父格单元格的值,但是C1有多个值, 这个时候输出如下
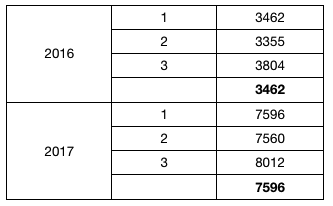
同行/同列引用多个值, 目标格获取原则
由上面的例子可以看出,当前格与目标格同行/同列 如果目标格有多个则取第一个;
# 非同行同列
如果当前单元格与目标单元格不在同一行或列,那情况是怎么样的,我们来看下一个例子。

在上面的例子中,我们在 C2 单元格的表达式中输入 B1,表示取 B1 单元格的值,但 B1 单元格又和 C2 不在同一行或列上,同时 B1 单元格展开后会有多个值,
但 B1 单元格和 C2 单元格都拥有一个共同的父格或间接父格 A1(C2 单元格的左父格是 B2,而 B2 单元格的左父格又是 A1,所以 A1 是 C2 单元格的间接左父格),
所以它会取他们共同父格 A1 下所有 B1 的值,运行结果如下图所示:
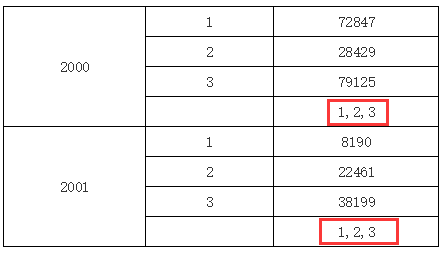
多个值的输出
如果取到值超过一个,输出时多个值间以“,”分隔,如上图所示
目标格获取原则
由上面的例子可以看出,单元格表达式在取目标格值时,如果不在同行/同列, 则取与当前单元格有共同父格的所有目标单元格,
如果他们有共同的上父格或共同的左父格,那么就取共同上父格与共同左格交集部分的目标单元格;如果他们没有共同的父格,那么就取迭代后所有的目标单元格。
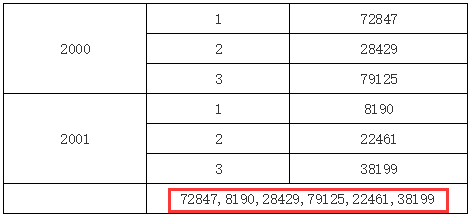
再看下面的报表示例:

在上面的例子中,B2 单元格表达里输入 C1,因为 B2 和 C1 既不在同一行或列,也没有共同的父格,所以 B2 中将取到所有的 C1 单元格的值,如下图所示:
# 更改父格实现单元格取值
上面没有修改父格的前提下取值时所谓的同行同列其实就是默认的父子格关系,目标格取值受当前格与目标格父格的影响。
所以,我们可以利用更改当前单元格的上父格或左父格使得当前单元格与目标格处于某个特定的父格下,从而改变取值范围。
通过修改当前格的父格对目标格求和
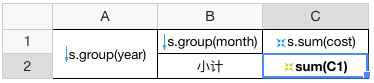
简单原则
修改当前格的父格与目标格的父格一致即可对目标格求和,上例我们要求每年C1的和,C2与C1有共同的年份左父格,则左父格不需要修改,C1的上父格为无,我们把C2原本的上父格修改为无即可
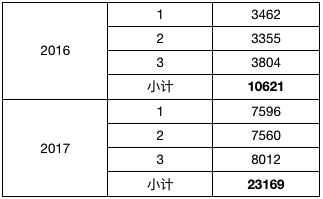
结果如下
# 特殊表达式
# #号表达式
#号表达式为当前单元格的内容
# 单元格明细数据行的属性过滤
过滤条件配置中右值(比较值)支持属性表达式 #.属性名,用于配置数据集中两个不同属性的比较,如下图所示,统计进入指标之前,需要过滤的点击数 > 进入数的脏数据,然后进行汇总
提示
#号也可以换成数据集的名称如:clk.进入
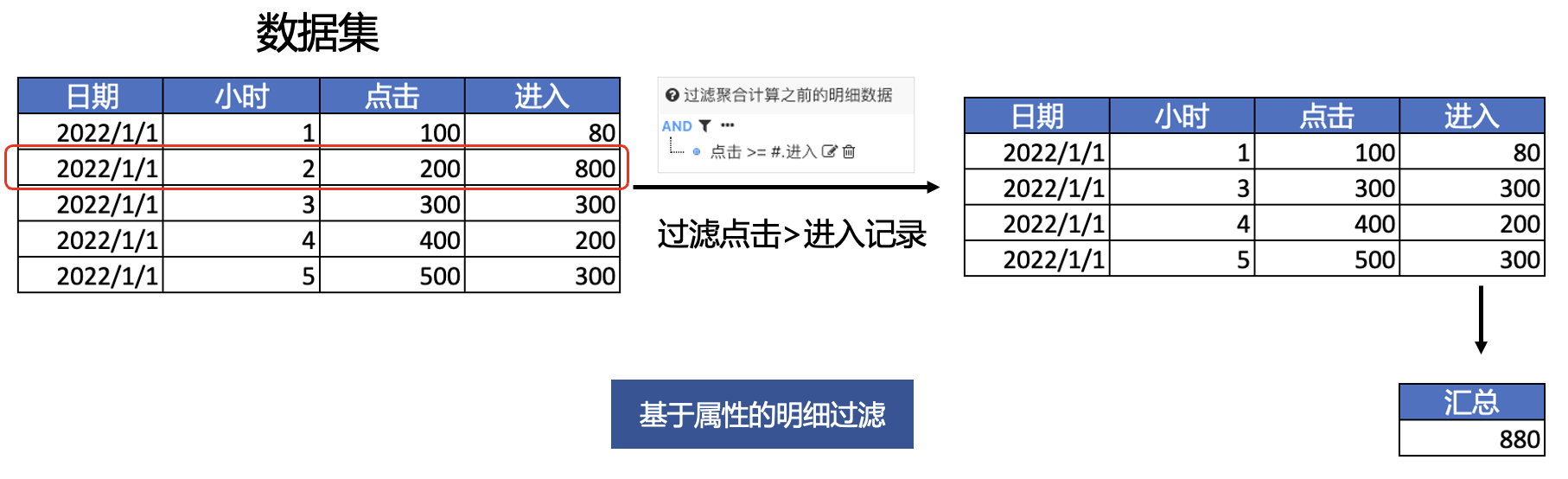

表达式实现
clk.sum(进入, 点击 >= 进入)
或者
clk.sum(进入, clk.点击 >= clk.进入)
1
2
3
2
3
# &目标单元格名称
单元格序号, 使用“&目标单元格名称”来标记目标单元格展开后的序号时,当前单元格必须是目标单元格的子格或间接子格;
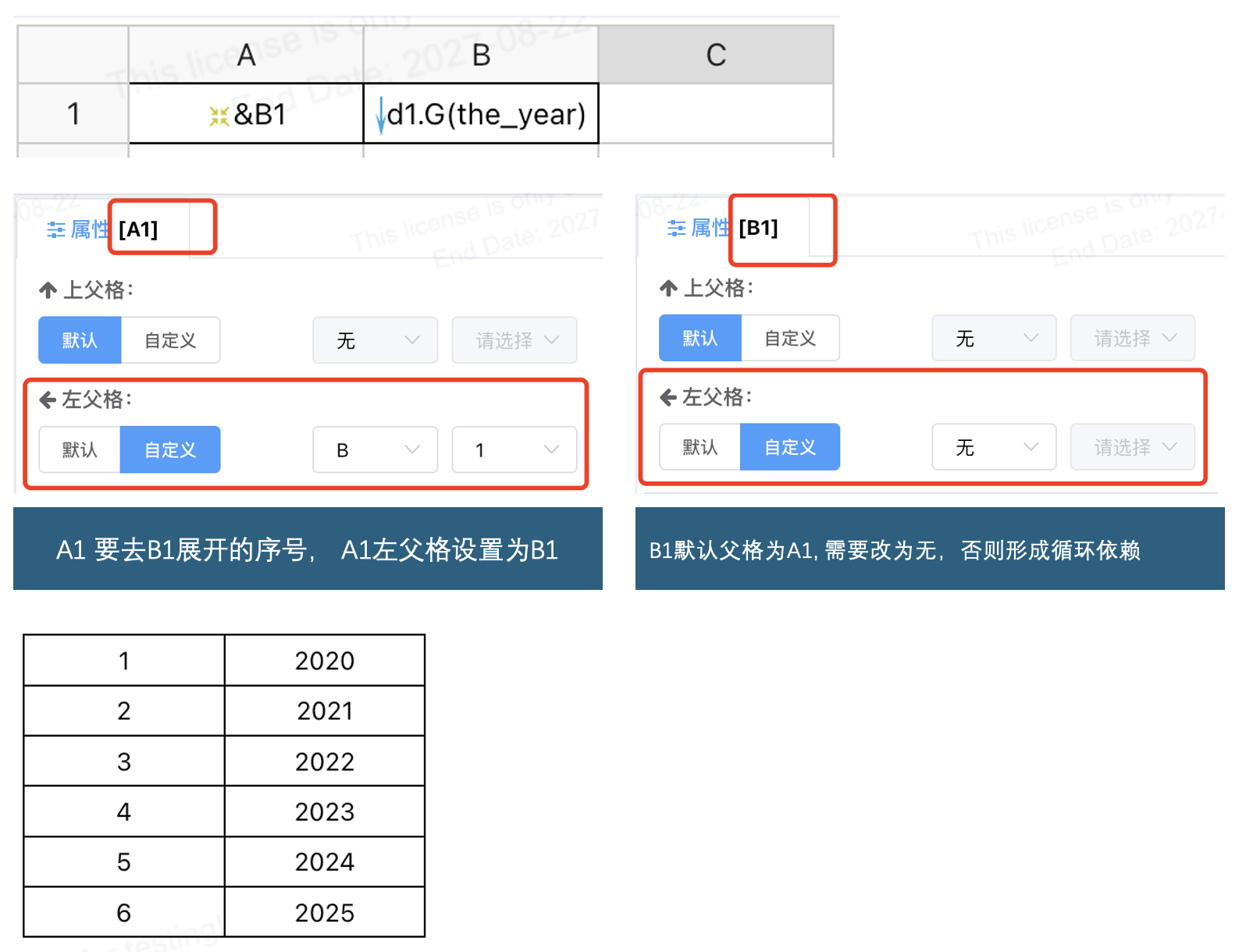
# 单元格坐标
为了实现更为复杂的单元格引用,UReport2 引入了单元格坐标的概念。单元格坐标,也是相对于当前单元格来进行计算的,同样遵循上面的介绍的优先取同行、同列或共同父格的原则,
IBI在UReport2的语法基础上做了一些调整
单元格名称[左父格坐标(, 左父格坐标)* ; 上父格坐标(, 上父格坐标)*]{条件...}
父格坐标语法
父格单元格名称@i, i为整数,表示父格展开之后第i个(从1开始计数)元素, 其中两个特殊的语法:
@i不写或者i=0,取所有父格对应的单元格可用于计算占比,@!-i相对坐标可用于计算环比
左父格坐标可以没有, 这样可以在没有左父格的前提下做偏移计算
单元格名称[;上父格坐标(, 上父格坐标)*]{条件...}
表示对通过坐标取到的单元格进行条件过滤,条件部分是可选的
# 实例
C2[A2]
当前单元格相对A2展开值对应的所有C2子格,常用来做分类统计
报表模板如下:

结果, 统计当前年份A2下每月的占比
C1[A1@!-1]
相对偏移坐标:当前单元格相对A1展开值上移一格对应的所有C1子格,常用来做环比统计
C1[A1@2, B1@1]
在找 C1 时先找单元格 A1 展开后的第2格;再找第二个 A1 下的 B1 单元格展开后的第一个单元格,然后再找这个 B1 单元格对应的 C1 单元格
C2[A1@2, B1@2; C1@3]
在找 C2 时,先找 A1 单元格展开后的第二格,再找第二个 A1 单元格下 B2 单元格展开后的第二格,再根据第二个展开的 B2 单元格找其下名为 C2 单元格的左子格; 然后再找到 C1 单元格展开后的第三格,再看其下的 C2 单元格,取 C2 单元格的交集
C2[A1@2, B2@2]{C2>10 and C2<100}
表示取 A2 单元格展开后的第二格,再取其下 B2 单元格展开后第二格,再取 B2 下所有的 C2 单元格,最后再对取到的 C2 单元格进行条件过滤,只取出 C2 单元格值大于10且小于100的所有 C2 单元格的值。
我们来看一个报表模版如下:

在上面的报表模版中,在 B2 单元格表达式里输入 C1[A1@2, B1@1], 这就表示取 A1 单元格展开后第二格下 B1 单元格展开后第一格下对应的 C1 单元格的值,所以运行后我们可以看到如下图所示效果:
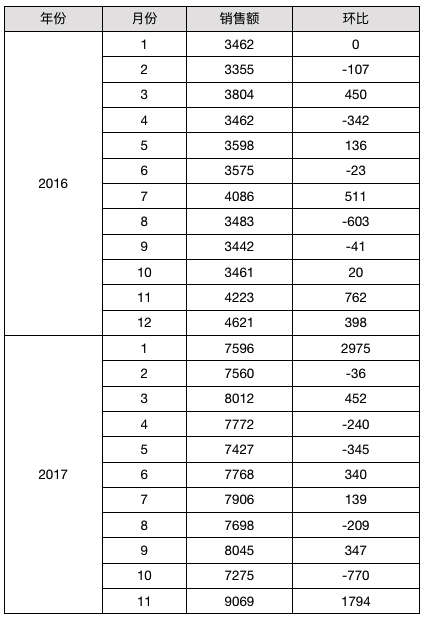
# 环比
报表模板如下:

C2 - C2[B2@!-1]
C2[B2@!-1]取相对于当前单元格的 B2 单元格上一格(感叹号负值表示向上位移)的B2单元格所对应的 C2 单元格
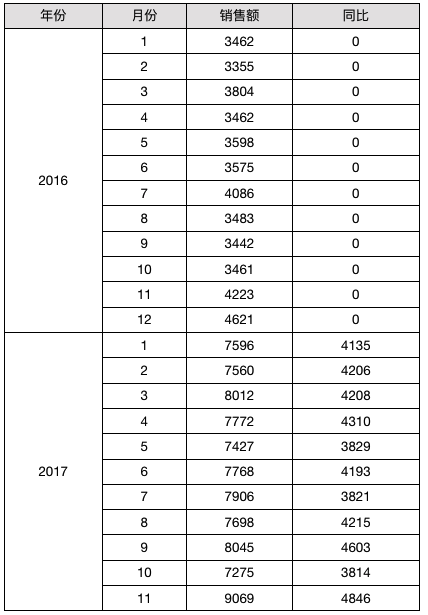
# 同比
报表模版如下图所示:

在上面的模版当中,D2 单元格中首先取到与其同行的 C2 单元格的值,然后利用单元格坐标,先取到当前 D2 单元格所在行的 A2 单元格的上一条 A2 单元格记录(@-1表示坐标上移),
然后再取这个 A2 下对应的 C2 单元格,但由于其下 C2 单元格还是有多个,所以这里加了个条件B2==$B2,
这里的第一个 B2 表示当前单元格所在行对应的 B2 的值,$B2 表示坐标定位后 C2 单元格对应的 B2 单元格的值,条件就是他们俩要相等,实际上就是月份相等,这样就达到了我们要实现的同比的目的
关于$B2
在单元格名称前加$符号,表示取相对于目标单元格的单元格的值,多用在条件比较当中,比如上面的C2[A2@!-1]{B2==$B2},这里的$B2就是指取到的C2单元格对应的B2单元格的值。
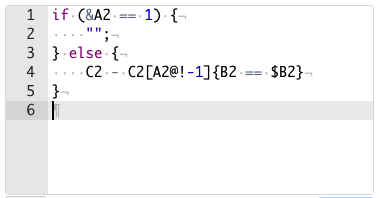
首年填写空白
可以通过改写表达式
关于&标记的使用
在使用“&单元格名称”来标记目标单元格展开后的序号时,除上需要注意上面描述的内容外,还需要注意,取序号将以他们共同的父格为基准,如果他们有共同的父格,那么将以这个父格里目标单元格的数量来进行序号编排,这在之前视频教程介绍报表计算模型中,实现明细型主从报表,对从表数据进行编号时就有体现。
隐藏首年
可以通过配置D2的条件属性配置, &A2==1, A2展开第一个元素对应的行高0
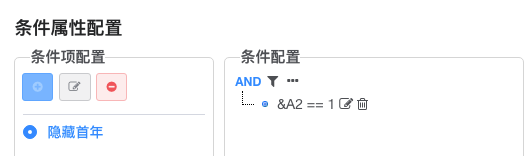
效果如下
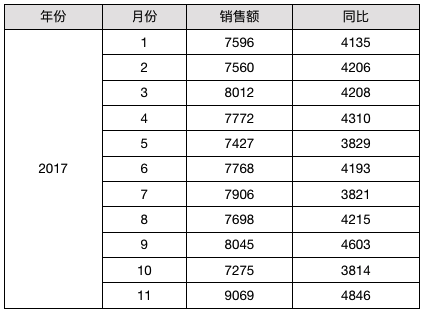
# 累加
报表模板如下:

D2 单元格对应的表达式如下:
C2 + D2[B2@!-1]
1
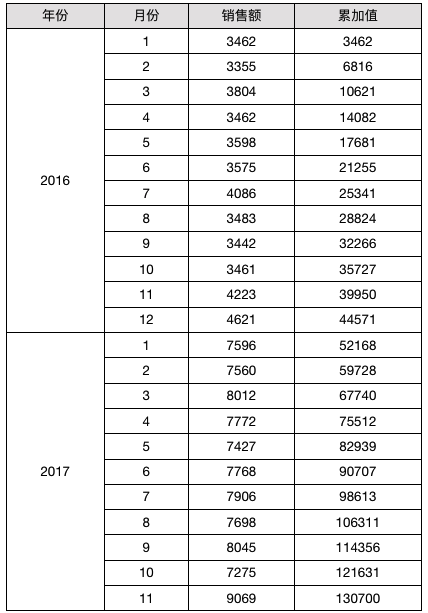
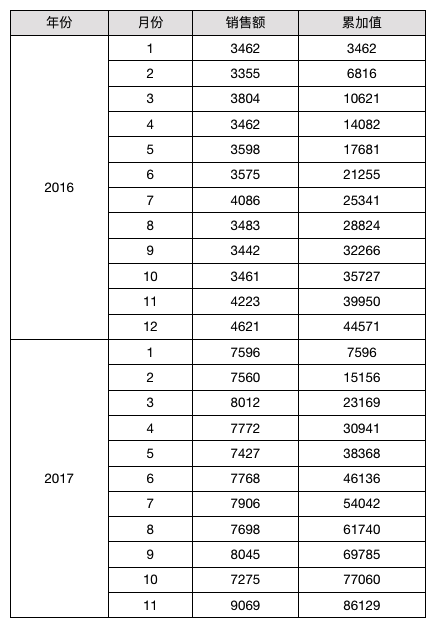
按年分组累加
-- 新的月份展开坐标为1的时候重新累加
if (&B2 == 1) {
return C2
} else {
return C2 + D2[B2@!-1]
}
1
2
3
4
5
6
2
3
4
5
6
结果如下
# 占比
用于统计C2数据列所有数据的总和
| 实例 | 说明 |
|---|---|
| C2/sum(C2[]) | 总占比 |
| C2/sum(C2[A2, B2]) | 按A2 + B2分类占比 |
| C2/sum(C2[]{A2 == $A2 and B2 == $B2}) | 按A2 + B2分类占比 |
报表模板如下:
结果
Tips
上面累加分母在取出分组对应单元格数组之后使用了sum()函数,具体函数相关介绍请参考函数章节
# 数据集表达式
数据集单元格其实也是表达式的一种,还允许我们在单元格表达式里通过书写表达式来实现单元格与数据集字段的绑定,其语法结构如下:
数据集名称.aggType(字段名[,条件,排序方式])
聚合方式与我们双击添加字段绑定后在属性面板上看到的聚合方式基本一致,具体有以下几种类型。
聚合方式/aggType:
select, group, sum, avg, count, min, max, distinct
| 实例 | 说明 |
|---|---|
| ds1.aggType(username) | 取数据集 ds1 中所有的 username 字段信息 |
| ds1.aggType(username, age > 18) | 增加过滤 |
| ds1.aggType(username, indexof(dst.name, 'a') > -1) | 如果过滤条件中属性需要函数处理,需要给属性加上数据集名称 |
| ds1.aggType(username, age > 18, desc) | 增加排序,sum, avg, count, min, max, distinct 输出为单值的不需要排序 |
| ds1.aggType(username, age>18 and age<60, asc) | 多条件过滤 |
# 属性函数判断
如果过滤条件中属性需要函数处理,需要给属性加上数据集名称
ds1.aggType(username, indexof(dst.name, 'a') > -1)
1